���]ϵ�y(t��ng)���d��� ����Windows10ϵ�y(t��ng)���d ����Windows7ϵ�y(t��ng)���d xpϵ�y(t��ng)���d ��X��˾W(w��ng)indows7 64λ�b�C(j��)�f(w��n)�ܰ����d

��W(w��ng)eb Scraper���d��Web Scraper�W(w��ng)�(y��)���x��� v0.5.4 ���°�
- ܛ����ͣ�����ܛ��
- ܛ���Z(y��)�ԣ���(ji��n)�w����
- �ڙ�(qu��n)��ʽ�����M(f��i)ܛ��
- ���r(sh��)�g��2024-11-18
- ��x��(sh��)����
- ���]�Ǽ�(j��):
- �\(y��n)�Эh(hu��n)����WinXP,Win7,Win10,Win11
ܛ����B
Web Scraper��һ��dz����õľW(w��ng)�(y��)���x����������Ԏ����Ñ��p��ץȡ�W(w��ng)վ�ϵ����Д�(sh��)��(j��)��(n��i)�ݣ������Ñ���ȫ����Ҫ�����κδ��a��Web Scraper�m���ڸ��N��͵ľW(w��ng)վ��߀֧��ץȡ�ă�(n��i)��(d��o)����CSV��ʽ���ļ�������Ҫ���Ñ�������d�ɡ�
Web Scraper��ɫ����
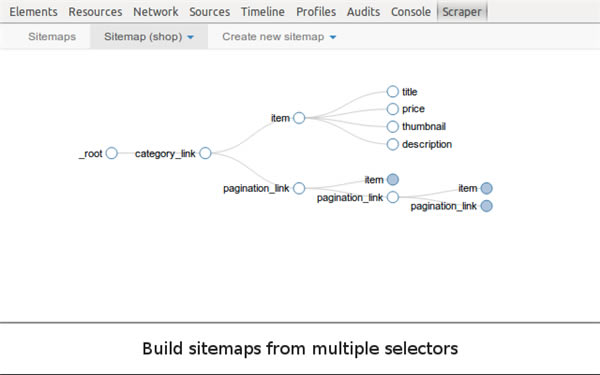
һ��(g��)��(ji��n)�ľW(w��ng)�(y��)���x��������Ԏ����������a���Ñ�(sh��)�F(xi��n)��(sh��)��(j��)��ȡ���ܡ�
ʹ�ô˔U(ku��)չ�������Ԅ�(chu��ng)��һ��(g��)sitemap(վ�c(di��n)�؈D)������ԓ��α�v�W(w��ng)վ�Լ���(y��ng)��ȡ��Щ��(n��i)�ݵȡ�
ʹ���@Щsitemap��Web Scraper������(y��ng)�،�(d��o)��վ�c(di��n)����ȡ���Д�(sh��)��(j��)��
�Ժ��Ԍ��ѺY�x�Ĕ�(sh��)��(j��)��(d��o)����CSV��
Web Scraperʹ�ý̳�
1����(bi��o)���(y��)ݔ�롾chrome://extensions/���M(j��n)��chrome�U(ku��)չ���≺���ڱ��(y��)���d��Web Scraper�����������U(ku��)չ�����(y��)���ɡ�
2��������b��ɺ��ڞg�[���Е�(hu��)���F(xi��n)�䰴�o��(bi��o)ӛ���Ñ����������O(sh��)���(y��)���Ќ�(du��)ԓ����ă�(ch��)���O(sh��)�ú̓�(ch��)��������M(j��n)���O(sh��)�á�
3���Ñ�����ʹ��Web Scraper�����ץȡ�(y��)�棬������������£�
1)�����_��Ҫץȡ�ľW(w��ng)�(y��)��
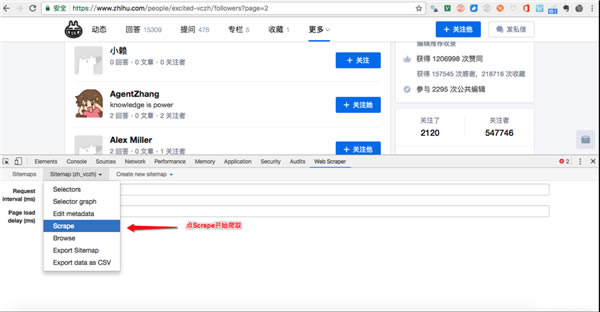
����Ҫʹ��ԓ�������ȡ�W(w��ng)�(y��)��(sh��)��(j��)��Ҫ���_�l(f��)�߹���ģʽ��ʹ�ã�ʹ�ÿ���ICtrl+Shift+I/F12�����c(di��n)�����I���x��“�z��(Inspect)”�����_�l(f��)�߹���������ܿ���WebScraper��Tab�����D��ʾ��
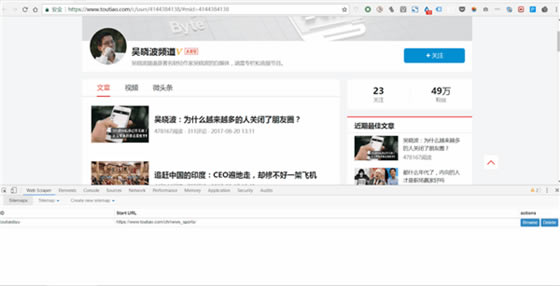
2)���½�һ��(g��)Sitemap���c(di��n)��Create New Sitemap�������Ѓɂ�(g��)�x�(xi��ng)��import sitemap��ָ��(d��o)��һ��(g��)�F(xi��n)�ɵ�sitemap����С��һ��]�ЬF(xi��n)�ɵģ�����һ�㲻�x�@��(g��)���xcreate sitemap �ͺá�
Ȼ���M(j��n)���@�ɂ�(g��)������
(1)Sitemap Name���������@��(g��)Sitemap���m������һ��(g��)�W(w��ng)�(y��)�ģ���������Ը���(j��)�W(w��ng)�(y��)�������������^��Ҫʹ��Ӣ����ĸ��������ץ���ǽ����^�l�Ĕ�(sh��)��(j��)�����Ҿ���toutiao��������
(2)Sitemap URL���ѾW(w��ng)�(y��)朽ӏ�(f��)�Ƶ�Star URL�@һ�ڣ�����DƬ���Ұѡ��ǕԲ��l���������(y��)朽ӏ�(f��)�Ƶ����@һ�ڣ������c(di��n)���·���create sitemap���½�һ��(g��)Sitemap��
3)���O(sh��)���@��(g��)Sitemap
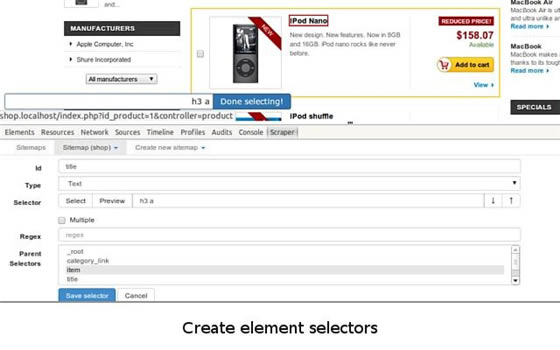
����(g��)Web Scraper��ץȡ߉���@�ӣ��O(sh��)��һ��(j��) Selector���x��ץȡ��������һ��(j��) Selector ���O(sh��)�ö���(j��) Selector���x��ץȡ�ֶΣ�Ȼ��ץȡ��
��(du��)�����¶��ԣ�һ��(j��) Selector ������Ҫ���@һ�K���µ�Ҫ��Ȧ�������@��(g��)Ҫ�ؿ��ܰ����� ��(bi��o)�}�����ߡ��l(f��)���r(sh��)�g���u(p��ng)Փ��(sh��)�ȵȣ�Ȼ���҂�?c��)��ڶ��?j��) Selector �������҂�Ҫ��Ҫ�أ������(bi��o)�}�����ߡ���x��(sh��)��
�����҂�������@��(g��)�O(sh��)��һ��(j��)������(j��) Selector �Ĺ�������
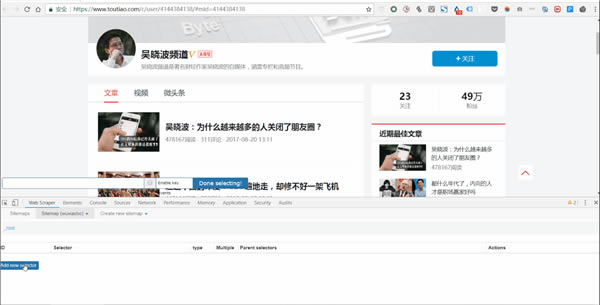
(1)�c(di��n)�� Add new selector ��(chu��ng)��һ��(j��) Selector��
���������²��E������
ݔ��id��id������ץȡ������(g��)�����������@�������£��҂�����������wuxiaoboarticles��
�x��Type��type ������ץȡ���@���ֵ���ͣ�����Ԫ��/�ı�/朽ӣ���?y��n)��@��(g��)������(g��)����Ҫ�ط����xȡ���҂���Ҫ��Element �������w�xȡ(����@��(g��)�W(w��ng)�(y��)��Ҫ����(d��ng)���d���࣬�Ǿ��x Element Scroll Down)��
���xMultiple�����x Multiple ǰ���С����?y��n)���Ҫ�x���Ƕ���(g��)Ԫ�ض����dž�(g��)Ԫ�أ���(d��ng)�҂����x�ĕr(sh��)�����x�����(hu��)�����҂��R(sh��)�e��ƪͬ����£�
�����O(sh��)�ã�����δ�ἰ���ֱ���Ĭ�J(r��n)�O(sh��)�á�
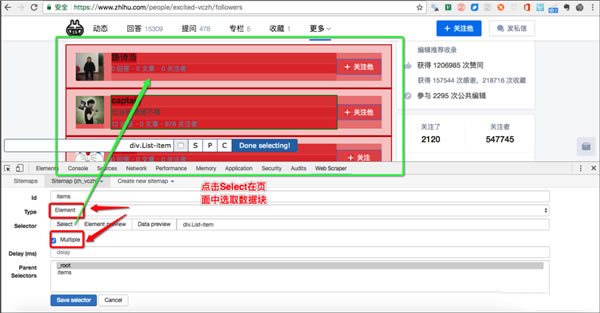
(2)�c(di��n)��select�x�����������²��E������
�x���������(bi��o)�x����Ҫ��ȡ��(sh��)��(j��)�ķ������Gɫ�Ǵ��x�^(q��)�������(bi��o)�c(di��n)����׃?y��u)�tɫ�������x�����@�K�^(q��)��
���x����Ҫֻ�xһ��(g��)�������ҲҪ�x����t�������Ĕ�(sh��)��(j��)Ҳֻ��һ�У�
����x��ӛ���c(di��n)Done Selecting��
���棺�c(di��n)��Save Selector��
(3)�O(sh��)�ú����@��(g��)һ��(j��)��Selector֮���c(di��n)�M(j��n)ȥ�O(sh��)�ö���(j��)��Selector���������²��E������
�½�Selector���c(di��n)�� Add new selector ��
ݔ��id��id������ץȡ�����Ă�(g��)�ֶΣ����Կ���ȡԓ�ֶε�Ӣ�ģ�������Ҫ�x�����ߡ����Ҿ͌���writer����
�x��Type���xText����?y��n)���Ҫץȡ�����ı��?/p>
���xMultiple����Ҫ���x Multiple ǰ���С����?y��n)��҂��(c��)��@��Ҫץȡ���dž�(g��)Ԫ�أ�
�����O(sh��)�ã�����δ�ἰ���ֱ���Ĭ�J(r��n)�O(sh��)�á�
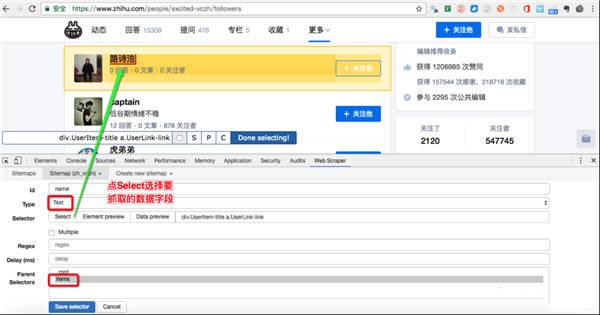
(4)�c(di��n)�� select�����c(di��n)����Ҫ��ȡ���ֶΣ��������²��E������
�x���ֶΣ��@����ȡ���ֶ��dž�(g��)�ģ������(bi��o)�c(di��n)��ԓ�ֶμ����x��������Ҫ����(bi��o)�}���Ǿ������(bi��o)�c(di��n)��ijƪ���µĘ�(bi��o)�}����(d��ng)�ֶ����څ^(q��)��׃�t�����x�У�
����x��ӛ���c(di��n) Done Selecting��
���棺�c(di��n)�� Save Selector��
(5)�؏�(f��)���ϲ�����ֱ���x�����������ֶΡ�
4����ȡ��(sh��)��(j��)
(1)֮������Ҫ��ȡ��(sh��)��(j��)ֻ��Ҫ�O(sh��)�������е�Selector�Ϳ����_ʼ��
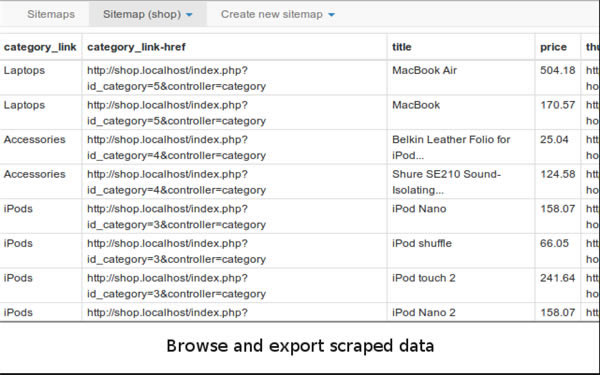
�c(di��n)��Scrape��Ȼ���c(di��n)Start Scraping������һ��(g��)С�������x�͕�(hu��)�_ʼ���������(hu��)�õ�һ��(g��)�б�������������Ҫ�����Д�(sh��)��(j��)��
(2)�����ϣ�����@Щ��(sh��)��(j��)��һ��(g��)�����簴����x����ٝ��(sh��)�����ߵ�ָ��(bi��o)������(sh��)��(j��)��һĿ��Ȼ����ô������c(di��n)�� Export Data as CSV��������(d��o)�� Excel ���
(3)��(d��o)�� Excel ����֮����Ϳ��Ԍ�(du��)��(sh��)��(j��)�M(j��n)�кY�x�ˡ�
�҂��@��ֻ�Ǻ�(ji��n)�ν�B���Y(ji��)��Web Scraper�IJ���Ĺ��ܣ����b�Լ�һ��(g��)��(ji��n)�εĆ��(y��)�����ӡ��䌍(sh��)Web Scraper�Ĺ����h(yu��n)�h(yu��n)��ֹ�ڴˣ��䌍(sh��)߀��ץȡ���(y��)��߀�ܶ��(y��)��Ԫ�ص�ץȡ��߀��ץȡ����(j��)�(y��)�档
1�M���ƽ̌W(xu��)ͨ2.0-�M���ƽ̌W(xu��)ͨ2.0���d v5......
2step7 microwin-���T��PLC S7......
3�ٶȾW(w��ng)�P��ˬ����(ji��n)������-�W(w��ng)�P����-�ٶȾW(w��ng)�P��ˬ��......
4360��ȫ�g�[��-�g�[��-360��ȫ�g�[�����d ......
5�ȸ�g�[�� XP��-�ȸ�g�[�� XP��-�ȸ�g�[......
6Kittenblock�ؑc�������ð�-�C(j��)���˾���......
7seo�������(����(j��)���) -SEO��會�(y��u)������......
8Notepad3-ӛ�±�ܛ��-Notepad3��......
9С���\(y��n)��(d��ng)ˢ����(sh��)����-С���\(y��n)��(d��ng)ˢ����(sh��)�������d v2......
1����\(y��n)��GHOST���bϵ�y(t��ng),��������\(y��n)���R���b�C(j��)
2Ů����ɶ���^��ã��m��Ů���\(y��n)�õ����^��_��
3���Ľ�����ΰ��bghostxpϵ�y(t��ng)
4�o�����(bi��o)�p�ĵĎNԭ�� �Լ�̎������
5Windows��������(j��)Win10ʧ����ʾ0x80...
6����(j��)Windows10 1607�汾�ľ��w�O(sh��)�÷�...
7win10��X�桶ֲ����(zh��n)��ʬ���W�˵�̎���k��
82018������^����ɶ��2018���Ů��...