���]ϵ�y(t��ng)���d��� ����Windows10ϵ�y(t��ng)���d ����Windows7ϵ�y(t��ng)���d xpϵ�y(t��ng)���d ��X��˾W(w��ng)indows7 64λ�b�C�f�ܰ����d

��SPSS���İ桿SPSS�e�����d v22.0 ��Xpc��
- ܛ����ͣ��k��ܛ��
- ܛ���Z�ԣ����w����
- �ڙ�(qu��n)��ʽ�����Mܛ��
- ���r�g��2025-02-08
- ��x��(sh��)����
- ���]�Ǽ�:
- �\�Эh(hu��n)����WinXP,Win7,Win10,Win11
ܛ����B
SPSS���İ���Statistical Product and Service Solutions����һ��I(y��)�Ĕ�(sh��)��(j��)�y(t��ng)Ӌ�ͷ���ܛ�����܉���Ñ����Ĕ�(sh��)��(j��)�M�нy(t��ng)Ӌ�������������\�㣬���Ҹ��ӱ�ݵĹ����@Щ��(sh��)��(j��)��ʹ���Ñ��܉�����������ҳ��@Щ��(sh��)��(j��)�����ߌ��@Щ��(sh��)��(j��)�M�о��ţ��Ñ����k���ĕr������p�㡣
SPSS���İ�ܛ����ɫ
��������
����dz��Ѻã����˔�(sh��)��(j��)��뼰�������������ٔ�(sh��)ݔ�빤����Ҫ�I�P�I���⣬�����(sh��)������ͨ�^�����ҷ���c��“�ˆ�”��“���o”��“��Ԓ��”����ɡ�
���̷���
���е��Ĵ��Z�Ե����c�����Vϵ�y(t��ng)Ҫ��ʲô���o����V��������ֻҪ�˽�y(t��ng)Ӌ������ԭ�����o��ͨ�Խy(t��ng)Ӌ�����ĸ��N�㷨�����ɵõ���Ҫ�Ľy(t��ng)Ӌ�����Y(ji��)�������ڳ�Ҋ�Ľy(t��ng)Ӌ������SPSS�������Z�䡢������x��헵��x��^����“��Ԓ��”�IJ�����ɡ���ˣ��Ñ��o�軨�����r�gӛ������������^�̡��x��헡�
������
���������Ĕ�(sh��)��(j��)ݔ�롢�����y(t��ng)Ӌ������������D�������ȹ��ܡ��Ԏ�11�N���136������(sh��)��SPSS�ṩ�ˏĺ��εĽy(t��ng)Ӌ���������s�Ķ����ؽy(t��ng)Ӌ�������������电(sh��)��(j��)��̽���Է������y(t��ng)Ӌ��������(li��n)�����������S���P�������P��ƫ���P������������Dž���(sh��)�z��Ԫ�ؚw������������f(xi��)����������Єe���������ӷ�������������Ǿ��Իؚw��Logistic�ؚw�ȡ�
��(sh��)��(j��)�ӿ�
�܉��xȡ��ݔ����N��ʽ���ļ���������dBASE��FoxBASE��FoxPRO�a(ch��n)����*.dbf�ļ����ı�����ܛ�����ɵ�ASC��(sh��)��(j��)�ļ���Excel��*.xls�ļ��Ⱦ����D(zhu��n)�Q�ɿɹ�������SPSS��(sh��)��(j��)�ļ����܉��SPSS�ĈD���D(zhu��n)�Q��7�N�D���ļ����Y(ji��)���ɱ����*.txt��html��ʽ���ļ���
ģ�K�M��
SPSS for Windowsܛ���֞����ɹ���ģ�K���Ñ����Ը���(j��)�Լ��ķ�����Ҫ��Ӌ��C�Č��H������r�`���x��
ᘌ��ԏ�
SPSSᘌ����W�ߡ��쾚����ͨ�߶����^�m�á����Һܶ�Ⱥ�wֻ��Ҫ���պ��εIJ��������������A��SPSS����Ѧޱ�ġ�����SPSS�Ĕ�(sh��)��(j��)������һ��Ҳ�^�m���ڳ��W�ߡ�����Щ�쾚��ͨ��Ҳ�^ϲ�gSPSS�������������ͨ�^���́팍�F(xi��n)������Ĺ��ܡ�
SPSS���İ�ܛ������
��(sh��)��(j��)����
��10���Ժ�SPSS��ÿ�������汾��������(sh��)��(j��)����������һЩ���M����ʹ�Ñ���ʹ�ø��鷽�㡣13���еĸ��M������Ҫ�����ׂ����棺
1�����L׃��������12���У�׃�����ѽ�(j��ng)�����Ԟ�64���ַ��L�ȣ�13���п���߀Ҫ���Ō��@һ���ƣ����_����������N���s��(sh��)��(j��)�}����õļ����ԡ�
2�����M��Autorecode�^�̣�ԓ�^�̌�����ʹ���ԄӾ��aģ�棬�Ķ��Ñ������Զ��x���������Ĭ�J��ASCII�a����M��׃��ֵ���ؾ��a�����⣬Autorecode�^�̌�����ͬ�r������׃���M���ؾ��a������߷���Ч�ʡ�
3�����M������/�r�g����(sh��)�����εĸ��M��������ʹ�Ãɂ�����/�r�g��ֵ��Ӌ�㣬�Լ�������׃��ֵ�����p���������ϡ�
�Y(ji��)�����
��10���𣬌���(sh��)��(j��)�ͽY(ji��)���ĈD���ʬF(xi��n)����һֱ��SPSS���M�����c����16���У�SPSS�Ƴ���ȫ�µij�Ҏ(gu��)�D���ܣ��������Ҳ�_���˱��^���Ƶĵز���13�挢ᘌ�ʹ���г��F(xi��n)��һЩ���}���Լ��Ñ������D���������Mһ���ĸ��ơ�
1���y(t��ng)Ӌ�D���ڽ�(j��ng)�^һ���ʹ�ú��µij�Ҏ(gu��)�D���������ѻ������ƣ����εĸ��M��ʹ�ò����������⣬߀ͻ���˃ɂ����c�������ڳ�Ҏ(gu��)�D���������Ľ����D���ܣ���D�M��Paneled charts�������`��ķ�D�����`��l�D�;��D�����SЧ���ĺ��Ρ��ѷe�ͷֶ�D�ȡ����������N�µĈD�Σ���֪�����˿ڽ��������c�ܶȈD�ɷN��
2���y(t��ng)Ӌ������ȫ���^�̵�ݔ�������������ı����Ğ�����^�Ę��S�������Ҙ��S���ı��F(xi��n)�������ԕ��õ��Mһ������ߣ���������һЩ�µĹ��ܣ�����Ԍ��y(t��ng)Ӌ���M�������ڱ����кϲ�/ʡ������С�ݔ���ȡ����⣬���S�팢���Ա�ֱ�ӌ�����PowerPoint�У��@Щ�o�ɶ��������Ñ���ʹ�á�
�y(t��ng)Ӌ��ģ
Complex Samples��12����������ģ�K�����ڌ��F(xi��n)���s��ӵ��OӋ�������Լ��������Ĕ�(sh��)��(j��)�M�������������r��δ�ṩ�y(t��ng)Ӌ��ģ���ܡ���13���У��@�����кܴ�ĸ��^��һ�㾀��ģ�͌�����������������s���ģ�K�У��Ԍ��F(xi��n)�����s����о��и��N�B�m(x��)��׃���Ľ�ģ�A�y���ܣ����猦�Ј��{(di��o)���еĿ͑��M��Ȕ�(sh��)��(j��)�M�н�ģ�����ڷ��(sh��)��(j��)��Logistic�ؚw�t������ϵ�y(t��ng)�����롣�@�ӣ�����һ��������s�ij���о�������A�η���Ⱥ��ӣ����߸����s��PPS��ӣ��о��߶�������ԓģ�K���p�ɵČ��F(xi��n)�ij���OӋ���y(t��ng)Ӌ���������s�y(t��ng)Ӌ��ģ�l(f��)�F(xi��n)Ӱ����ص����������^�̣��������ģ�͡����λؚwģ�͡�Logistic�ؚwģ�͵ȏ��s�Ľy(t��ng)Ӌģ�Ͷ����Լ���ʹ�ã���������ʽ��������ȫ�S�C��Ӕ�(sh��)��(j��)�ķ��������]��ʲô��e�������AҊ��ԓģ�K���Ƴ����������M����(n��i)�����s��ӕr�y(t��ng)Ӌ�Ɣ�ģ�͵����_���á�
ģ�K
�@��ģ�K���H�Ͼ��nj���ǰ�Ϊ��l(f��)�е�SPSS AnswerTreeܛ�������M��SPSSƽ�_���P�ߎ���ǰ���Լ��ľW(w��ng)վ�Ͻ�BSPSS 11���¹��ܕr������(j��ng)�ܼ��J��ָ��SPSS�Įa(ch��n)Ʒ���^�ڷ�ɢ�������Ѹ��N�����^��һ��Сܛ������AnswerTree��Sample Power�����ϵ�SPSS�Ȏׂ�ƽ�_��ȥ������SPSS��˾Ҳ���R�����@һ�c����AnswerTree�����ڴ˱����µ�һ�����ص����ϵĮa(ch��n)Ʒ��
Classification Treeģ�K���ڔ�(sh��)��(j��)�ھ��аl(f��)չ�����Ę�Y(ji��)��(g��u)ģ�͌����׃�����B�m(x��)׃���M���A�y�����Է��㡢���ٵČ��ӱ��M�м��֣�������Ҫ�Ñ���̫��Ľy(t��ng)Ӌ���I(y��)֪�R�����Ј����ֺ͔�(sh��)��(j��)�ھ������^�V���đ��á���֪ԓģ�K�ṩ��CHAID��Exhaustive CHAID��C&RT���N�㷨����AnswerTree���ṩ��QUEST�㷨�в��ܿ϶��Ƿ�����{�롣
���˷��������Ñ���ʹ�ã�Treeģ�K�ڲ�����ʽ�ϲ���ʹ��AnswerTree�е���?q��)���ʽ������SPSS�������_ʼ���õĽ���ʽ�x헿���Ԓ���ǣ������x헿�����ă�(n��i)���H���Ǻ�ԭ�ȵ���?q��)�����һ�µģ����⣬ģ�͵ĽY(ji��)��ݔ����Ȼ��AnswerTree�И˜ʵĘ��ΈD���@ʹ��AnswerTree�����Ñ������ϲ���Ҫ���T�ČW�����܉����ʹ��ԓģ�K��
���ژ�Y(ji��)��(g��u)ģ�͵ķ����wϵ�͂��y(t��ng)�Ľy(t��ng)Ӌ������ȫ��ͬ���Q(m��o)Ȼ������ܕ������x�߽y(t��ng)Ӌ�����wϵ�Ļ�y����ˣ����ξ����ĸ��̳̲�δ��Bԓģ�K�������ڸ��̵̳���һ���汾���Լ��P���Ј����ֆ��}�Ľ̲��Ќ������Ԕ����B��
������
�S�������a(ch��n)Ʒ���IJ������ƣ�SPSS��˾�Įa(ch��n)Ʒ�wϵ�ѽ�(j��ng)��������������ͬ�a(ch��n)Ʒ�g�Ļ��a�ͼ�����Ҳ�ڲ�����Ը��M����13���У�SPSSܛ���ѽ�(j��ng)���Ժ�����һЩ���µĮa(ch��n)Ʒ�ܺõ�������һ���γɸ��������Ľ�Q���������磬SPSS��SPSS Data Entry���°l(f��)����SPSS Text Analysis for Surveysһ����γ��ˌ��{(di��o)���о���������Q��������������SPSS Classification Treesģ�K��ʹ��SPSSܛ���������܉�ᘌ��Ј����ֹ����ṩ���������ķ����wϵ��
SPSS���İ�ʹ�ý̳�
SPSS�Ќ���EXCEL��(sh��)��(j��)��
��������X�ϴ��_spssܛ��������]��spss��Ҫȥ���bһ�����c��spss��ݷ�ʽ���M��spss�D�β������档
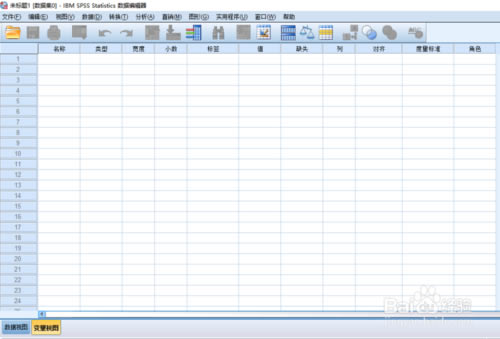
��spss�IJ��������ϣ��c�����Ͻ�“�ļ�”���ڲˆ����ҵ����_���c��“���_”�����¼��x����x��“��(sh��)��(j��)”��
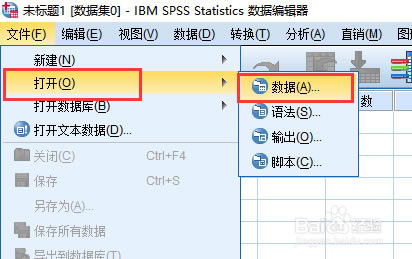
�c���Mȥ�ļ�������������@߅�x��������Ҫ���_��excel�ļ�����“���ҷ���”���x����excel��(sh��)��(j��)�ļ���ŵ��ļ��A�������������ļ�����x��excel�ļ���ͣ���Ȼ�Ҳ���excel�ļ���
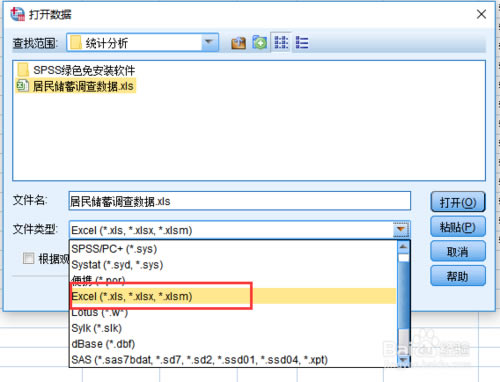
���x���excel��(sh��)��(j��)�ļ�֮�Γ���߅“���_”���o�����_excel�ļ����ڏ�������Ϣ�����x��“�_��”���_��
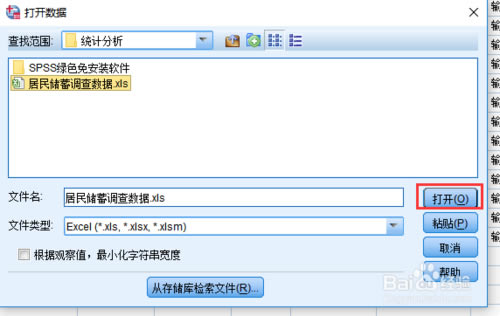
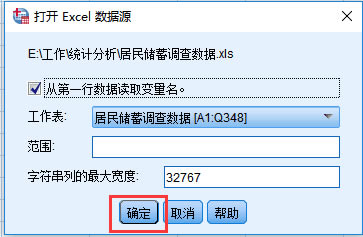
���_֮��spss�Ͱ�excel��(sh��)��(j��)�ļ����_�ˣ����������������������˺����N׃��ֵ���@�����҂��ͳɹ���spss̎��excel��(sh��)��(j��)�ļ��ˡ�
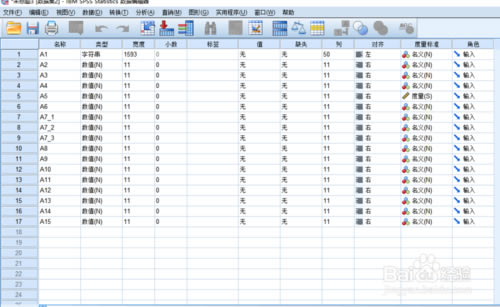
spss���ݔ�딵(sh��)��(j��)?
1�����ȴ��_SPSS�������M�����½��棬�@��������Ǵ��_֮��ij�ʼ��档
2���c�����Ͻǵ��ļ����½�һ���ļ����ļ�����O�Þ锵(sh��)��(j��)��
3���½��Y(ji��)�����҂����M�������½��档�м������½ǣ��֞锵(sh��)��(j��)ҕ�D��׃��ҕ�D��Ҫ��ݔ�딵(sh��)��(j��)���҂�������O�ú�׃����
4���c��׃��ҕ�D�����ɳ��F(xi��n)���½��档�҂����Կ���׃��ҕ�D�У���һ��׃�������O�õİ������Q����͡����ȡ�С��(sh��)���˺�����ֵ���O����͡�
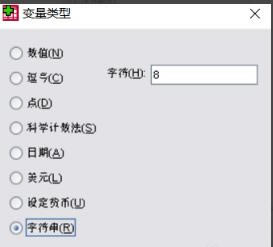
5���@���҂��O�Ãɂ�׃�����քe�����������g�������O�Þ��ַ����ͣ����Ȟ�8λ��С��(sh��)λ��0
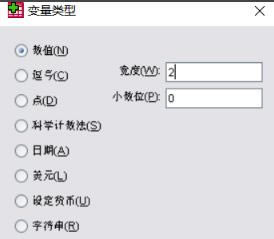
6�����g�O�Þ锵(sh��)ֵ�ͣ����Ȟ�2λ��С��(sh��)λ��0��
7�����@Щ�O����ɺ��ɳ��F(xi��n)���н��棬��ʾ׃�����x��ɡ�
8��Ȼ���c������ԓ�ęn���ļ�——���棩������һ���Լ�ӛ�õ�λ�ã������´ο��Կ����ҵ�����
9������ɹ����҂��ٻص������ѽ�(j��ng)������@�������У��c�����½ǵĔ�(sh��)��(j��)ҕ�D���Ϳ���ݔ�딵(sh��)��(j��)��
SPSS���İ泣Ҋ���}
��SPSS�У�����M�з����R�ԙz���?������ʲô?
�������(AnaylsisofVariance,ANOVA)Ҫ����M�������R�����^һ���J�飬������M�˔�(sh��)����������δ��ͨ�^�������R�z���}Ҳ����
One-WayANOVA��Ԓ���K�У��c��Options…(�x�…)��Ť����Homogeneity-of-variance���ɡ������a(ch��n)��Levene��CochranC��Bartlett-BoxF�șz�ֵ�����@����ˮƽPֵ����Pֵ<��0.05����ܽ^�������R�ļ��O��
혎�һ�ᣬCochran��Bartlett�z���������B(t��i)���ஔ���У������F(xi��n)���ܽ^�������R���ęz�y�Y(ji��)���������@ԭ������ɡ�
��SPSS���ܷ�ֱ���x��EXCEL97��(sh��)��(j��)�ļ�?�Пo�x�딵(sh��)��(j��)�ĺ��㷽��?
��SPSS10.0���У��κΰ汾��EXCEL�ļ���������OPEN��Ԓ����ֱ�Ӵ��_������9.0����ǰ�汾�оͱ��^���s�����H��SPSS7.0���ϵİ汾�������x��EXCEL97��ACCESS97�Ĕ�(sh��)��(j��)�ļ������@Щ�ļ���Ͳ����ڴ��_�ļ���Ԓ����ļ�������ҵ���SPSS������ODBC�팍�F(xi��n)���@Щ��(sh��)��(j��)�ļ����xȡ�ġ�������SPSS9.0�У�Ո�x��File�ˆ�->
newquery����������(sh��)��(j��)���xȡ��?q��)��Č�Ԓ����ʾ�������?�����܉��xȡ��ODBC��(sh��)��(j��)���ȡ�Q��������Ӌ��C�ϰ��b��ODBC�(q��)�ӳ���Ķ���)��
���H�ό����ϰ汾��SPSS���f���x��EXCEL97��(sh��)��(j��)�ļ���εķ���������EXCEL97���x�������蔵(sh��)��(j��)(��Ҫ�x��׃����)��Ȼ����SPSS��(sh��)��(j��)�������x��һ��һ�еĆ�Ԫ����(sh��)��(j��)ճ�N�^�������׃�����Ğ�ԭ׃��������׃���ٶ�ӛ䛔�(sh��)���r���@�N���������ġ�
��Ό�SPSS�ĽY(ji��)���ļ�(*.spo�ļ�)�D(zhu��n)�Q��������ʽ?
SPSS�ĽY(ji��)���ļ���7.0�汾����nj��õ�*.spo�ļ�����(j��)����֪��߀�]���ǷN����̎��ܛ�����Ԍ����x��������SPSS�ṩ�ˌ�ԓ�ļ��D(zhu��n)���������ʽ�Ĺ��ܡ���SPSS��OUTPUT�������x��File�ˆ�->export�����Ԍ��Y(ji��)���ļ������HTML�ļ���TXT�ļ�����Ȼ��Ҫ��spo�ļ��y���Ķࡣ�D��t�Ԅ��D(zhu��n)����JPG�DƬ�������پ�����ˣ�����������Ķ���ɺ���EXPORT�����⣬ԓ����Ҳ����ᘌ����DƬ������M�У��x������DƬ����Γ����I���x���ݲˆ��е�EXPORT���ɡ�
�댢SPSS�ĽY(ji��)������ֱ��ճ�N��WORD��ʹ�ã���һճ�^ȥ����ĸ�ʽ�́y�ˣ���α���ԭ�еĸ�ʽ?
�x��������Γ����I���x���ݲˆ��е�copyobject���ɣ��˕rճ�N�^ȥ�ı���͕�����ԭ�еĸ�ʽ(���H��ճ�N�^ȥ����һ���DƬ)��
�ڴ��_���е�Excel����r���Գɹ����x�딵(sh��)��(j��)����ͬ�r���F(xi��n)Output1-SPSSViewer�����@��ʲôԭ��?
ԓ��ʾ����˼��EXCEL����ĵ�12�е����еĔ�(sh��)��(j��)��SPSS�ĸ�ʽ�����ݣ��Ķ�ԓ��(sh��)ֵ���ܟo�����_���룬���ܵ�ԭ����С��(sh��)�c���λ��(sh��)̫�ࡣ�@��ҪՄ��һ�c���̵Ć��}��EXCEL��ACCESS�ȵ�Ĭ�J��(sh��)��(j��)�L�ȶ���24λ�ģ��oՓ��Č��H��(sh��)ֵ�����ȸ��Ǻ��£����@������Ҳ̫���ˣ�������С��(sh��)�c�������һ��ѵ�0���Ķ�����SPSS���܉���ܵľ��ȷ��������³��F(xi��n)���档�@�r����Ҫ�z��һ����Ĕ�(sh��)��(j��)�������f̫�L�����ߔ�(sh��)�����g������һ����̖�ȣ��S���r��?q��)�ԓ�е�Ĭ�J��(sh��)��(j��)��ʽ��һ�¾Ϳ����ˡ�
�����SPSS���İ����M�������OӋ����������?
����ǰ�Ԟ�SPSS�����������OӋ�����x�W(w��ng)��edof@sh�����ѣ���(j��ng)�о����������£�
�OҪ�������ص������OӋ��A����������ˮƽ��B�����Ѓɂ�ˮƽ���t�x��Data-->
generate�������ľ��������OӋ���ڣ�
Factorname��ݔ��A���Γ�ADD�o���Γ�Definevalue�o���քe��Value�е��^����ݔ��1��2��3���Γ�continue�o���@�ӾͶ��x����׃��A��
����Ƶķ������x��׃��B��2��ˮƽ���Γ�OK��ϵ�y(t��ng)��ݔ��һ���¶��x�Ĕ�(sh��)��(j��)����ǰ�ɂ�׃������Ҫ������A��B������ˮƽ�ѽ�(j��ng)�������OӋ��Ҫ�����к��ˡ������status_��card_׃����ϵ�y(t��ng)�a(ch��n)����LOG׃�������Բ��������F(xi��n)�����ٽ���һ���Y(ji��)��׃����ݔ�댍�Y(ji��)�����Ϳ����M�������OӋ�ķ����ˡ�
�����OӋ�ķ�����GLMģ�K�M�С����w��������
Univariate...dependent���x�둪׃����fixedfactor���x����׃����Ȼ���M��model�o�M��ģ���O�ã��@һ���dz���Ҫ!�O��ģ�͞�custom��Ȼ���x����Ҫ��������Ч���ͽ������á�Ȼ��_�J���Ϳ��Եõ�����Ҫ�ĽY(ji��)����
Ոע�⣬���model�o�M��ģ���O�Õr�x���e�`���t�õ��ĽY(ji��)���϶��Dz����_�ġ�
�����SPSS�����l��Logistic�ؚw�����͆�׃������?
A��SPSS���l��Logistic�ؚw�ǟo�ܞ����ģ������ԅ���SAS���ɽ���е�׃�Q��ʽ��ԭ��(sh��)��(j��)�M��׃�Q���M�ДM�ϡ����چ�׃���������ԭ׃���O����׃��(���x����CAT)���t�M�ϕr�S��ģ�͕��ԄӰ���׃���M�ϣ�������(sh��)��r�µ����Юa(ch��n)����׃����
SPSS�ܷ�������һ������ͬ�Ӕ�(sh��)��(j��)�Y(ji��)��(g��u)�Ĕ�(sh��)��(j��)�����(sh��)��(j��)?��ͬfoxpro�е�Replace����?
SPSS��DATA�ˆ��ṩ��MERGEFILES�^�̾������ڙM��Ϳv��ϲ���(sh��)��(j��)�ļ��ģ�һ����r�Ĕ�(sh��)��(j��)�ϲ����}ԓ�ˆζ����Խ�Q�����w�÷�Ո��Ҋ�W(w��ng)վ��SPSS�̵̳ڶ��¡�
��SPSS���Пo�����Z�ԿɌ�?��IF....Else..�Ⱦ����Z��?
SPSS����IF....Else..�Ⱦ����Z�䣬���H��Ҳ���������������Z��һ�ӵ�ʹ�á���������SPSS��SYNTAX���ھ���SPSS�������Q���ڽ̵̳ĵ��������к��εĽ�B�������s����r�����Ì��T��SPSSPRODUCTIONFACILITY����ɡ����^���҂����������Ķ���(sh��)���}�����òˆ���ɣ���COMPUTE�е�IF�ӲˆΣ�����Ҫȥ��SPSS����
�������(ANOVA)�����ӱ�����(sh��)�g�ăɃɱ��^����PostHoc��Ԓ�����ṩ�˃ɷN��ͬ��r�µ��x헣�Ո��EqualVarianceNotAssumed���ڷ���R�r�x�õĆ�?�������ṩ���ķNİ���ęz�����Խ�Bһ��?
�ǵģ��Ĵ_��ˣ��@Щ���������ڷ���R�r�x�õġ����^>�@�ķN�z����Ҳ����Ϥ�����H�ϳ���SNK��LSD���ٔ�(sh��)�N�����⣬���ڷ�������ăɃɱ��^��Փ�Ͼ͛]�нy(t��ng)һ�����������Ǹ��f���������Y(ji��)���lҲ�����l��������ȥ����SAS���@�ķN�z���������Ҳ���!��SPSS�Ď�����(n��i)�ݷ��g��������˼���£�
Tamhanes’sh2������T�z��һ�N���صăɃɱ��^������
Dunnetts’st3�����ژ˜ʻ����ϵ��(sh��)�ăɃɱ��^������
Games-howell���Еr�˜��^�ɵăɃɱ��^������
Dunnett’sC�����ژ˜ʻ�ȫ��ăɃɱ��^������
�����ķN�����ڷ���R�rʹ�òź��m��
SPSS��HomogeneousSubsets�µ�S-N-K�LJ���(n��i)�̿ƕ�����ָ��S-N-K����?���ṩ��LSD�������ڸ��M�g�ăɃɱ��^��?�����f�������������(n��i)�̿ƕ��д˷N��r������B��S-N-K����(�����֪��LSD���ڽ̿ƕ��������ڸ��ί��M�c���սM֮�g�Ƀɱ��^��)?
���f�Č�����S-N-K����S-N-K�����^SPSS�ṩ��LSD�����ܾ��@�Ӻ��εĴ���SNK�������ÿ�N�������������OӋ˼����m�÷�����LSD���ƌ��r�����ڼ��O��һ���˜ʌ��յ���r���M�еģ����������������ɽM�ăɃɱ��^���t�ஔ���S���׃��alphaˮ�ʣ���Ȼ�����ˡ�
1�M���ƽ̌Wͨ2.0-�M���ƽ̌Wͨ2.0���d v5......
2step7 microwin-���T��PLC S7......
3��Ѹ��Ӳ��v����ܛ��-��Ѹ��Ӳ��v����ܛ�����d ......
4���vӍ����ģ�M���Gɫ�����d���vӍ����ģ�M���Gɫ��......
5��Ք�(sh��)�W��X�˹ٷ�����2024���°�Gɫ���M���d......
6Archbeeܛ���ṩ���d-Archbee�͑���......
7�ٶȾW(w��ng)�P��ˬ����������-�W(w��ng)�P����-�ٶȾW(w��ng)�P��ˬ��......
8360��ȫ�g�[��-�g�[��-360��ȫ�g�[�����d ......
1����\��GHOST���bϵ�y(t��ng),��������\���R���b�C
2ϵ�y(t��ng)֮��һ�IU�P���bwindows7ϵ�y(t��ng)�D��Ԕ��...
3Ů����ɶ���^��ã��m��Ů���\�õ����^��_��
4���Ľ�����ΰ��bghostxpϵ�y(t��ng)
6Windows��������Win10ʧ����ʾ0x80...
7����Windows10 1607�汾�ľ��w�O�÷�...
8win10��X�桶ֲ����(zh��n)��ʬ���W�˵�̎���k��