���]ϵ�y(t��ng)���d��� ����Windows10ϵ�y(t��ng)���d ����Windows7ϵ�y(t��ng)���d xpϵ�y(t��ng)���d ��X��˾W(w��ng)indows7 64λ�b�C(j��)�f�ܰ����d

��SPSS17.0�����e�����d��SPSS17.0�y(t��ng)Ӌ�W(xu��)ܛ�� v17.0 �ٷ��汾
- ܛ����ͣ�ϵ�y(t��ng)ܛ��
- ܛ���Z�ԣ����w����
- �ڙ�(qu��n)��ʽ�����Mܛ��
- ���r�g��2024-10-19
- ��x��(sh��)����
- ���]�Ǽ�:
- �\�Эh(hu��n)����WinXP,Win7,Win10,Win11
ܛ����B
SPSS17.0�����e����һ��I(y��)�Ĕ�(sh��)��(j��)�y(t��ng)Ӌ��������ܛ��������(sh��)��(j��)��롢����������������һ�����Ñ�H���x�������c�����ɣ��ܷ���ď�������(sh��)��(j��)�����x�딵(sh��)��(j��)����ȫ���ԝM��ǽy(t��ng)Ӌ���I(y��)��ʿ�Ĺ�����Ҫ��
ܛ����ɫ
1����������
����dz��Ѻã����˔�(sh��)��(j��)��뼰�������������ٔ�(sh��)ݔ�빤����Ҫ�I�P�I���⣬�����(sh��)������ͨ�^���(bi��o)��ҷ���c��“�ˆ�”��“���o”��“��Ԓ��”����ɡ�
2�����̷���
���е��Ĵ��Z�Ե����c�����Vϵ�y(t��ng)Ҫ��ʲô���o����V��������ֻҪ�˽�y(t��ng)Ӌ������ԭ�����o��ͨ�Խy(t��ng)Ӌ�����ĸ��N�㷨�����ɵõ���Ҫ�Ľy(t��ng)Ӌ�����Y(ji��)�������ڳ�Ҋ�Ľy(t��ng)Ӌ������SPSS�������Z�䡢������x��헵��x��^����“��Ԓ��”�IJ�����ɡ���ˣ��Ñ��o�軨�����r�gӛ������������^�̡��x��헡�
3������(qi��ng)��
���������Ĕ�(sh��)��(j��)ݔ�롢�����y(t��ng)Ӌ������������D�������ȹ��ܡ��Ԏ�11�N���136������(sh��)��SPSS�ṩ�ˏĺ��εĽy(t��ng)Ӌ��������(f��)�s�Ķ����ؽy(t��ng)Ӌ�������������电(sh��)��(j��)��̽���Է������y(t��ng)Ӌ��������(li��n)�����������S���P(gu��n)�������P(gu��n)��ƫ���P(gu��n)������������Dž���(sh��)�z��Ԫ�ؚw������������f(xi��)����������Єe���������ӷ�������������Ǿ��Իؚw��Logistic�ؚw�ȡ�
4����(sh��)��(j��)�ӿ�
�܉��xȡ��ݔ����N��ʽ���ļ���������dBASE��FoxBASE��FoxPRO�a(ch��n)����*.dbf�ļ����ı�����ܛ�����ɵ�ASC��(sh��)��(j��)�ļ���Excel��*.xls�ļ��Ⱦ����D(zhu��n)�Q�ɿɹ�������SPSS��(sh��)��(j��)�ļ����܉��SPSS�ĈD���D(zhu��n)�Q��7�N�D���ļ����Y(ji��)���ɱ����*.txt��html��ʽ���ļ���
5��ģ�K�M��
ܛ���֞����ɹ���ģ�K���Ñ����Ը���(j��)�Լ��ķ�����Ҫ��Ӌ��C(j��)�Č��H������r�`���x��
6��ᘌ��ԏ�(qi��ng)
ᘌ����W(xu��)�ߡ��쾚����ͨ�߶����^�m�á����Һܶ�Ⱥ�wֻ��Ҫ���պ��εIJ��������������A��SPSS����Ѧޱ�ġ�����SPSS�Ĕ�(sh��)��(j��)������һ��Ҳ�^�m���ڳ��W(xu��)�ߡ�����Щ�쾚��ͨ��Ҳ�^ϲ�gSPSS�������������ͨ�^���́팍�F(xi��n)����(qi��ng)��Ĺ��ܡ�
ܛ������
������(qi��ng)�Ĕ�(sh��)��(j��)�������ܡ�
��10���Ժ�SPSS��ÿ�������汾��������(sh��)��(j��)����������һЩ���M(j��n)����ʹ�Ñ���ʹ�ø��鷽�㡣13���еĸ��M(j��n)������Ҫ�����ׂ����棺
1�����L׃��������12���У�׃�����ѽ�(j��ng)�����Ԟ�64���ַ��L�ȣ�13���п���߀Ҫ���Ō��@һ���ƣ����_(d��)������(d��ng)����N��(f��)�s��(sh��)��(j��)�}����õļ����ԡ�
2�����M(j��n)��Autorecode�^�̣�ԓ�^�̌�����ʹ���ԄӾ��aģ�棬�Ķ��Ñ������Զ��x���������Ĭ�J(r��n)��ASCII�a����M(j��n)��׃��ֵ���ؾ��a�����⣬Autorecode�^�̌�����ͬ�r������׃���M(j��n)���ؾ��a������߷���Ч�ʡ�
3�����M(j��n)������/�r�g����(sh��)�����εĸ��M(j��n)��������ʹ�Ãɂ�����/�r�g��ֵ��Ӌ�㣬�Լ�������׃��ֵ�����p���������ϡ�
�������ƵĽY(ji��)����湦�ܡ�
��10���𣬌���(sh��)��(j��)�ͽY(ji��)���ĈD���ʬF(xi��n)����һֱ��SPSS���M(j��n)�����c����16���У�SPSS�Ƴ���ȫ�µij�Ҏ(gu��)�D���ܣ��������Ҳ�_(d��)���˱��^���Ƶĵز���13�挢ᘌ�ʹ���г��F(xi��n)��һЩ���}���Լ��Ñ������D���������M(j��n)һ���ĸ��ơ�
1���y(t��ng)Ӌ�D���ڽ�(j��ng)�^һ���ʹ�ú��µij�Ҏ(gu��)�D���������ѻ������ƣ����εĸ��M(j��n)��ʹ�ò����������⣬߀ͻ���˃ɂ����c�������ڳ�Ҏ(gu��)�D���������Ľ����D�� �ܣ���D�M��Paneled charts�������`��ķ�D�����`��l�D�;��D�����SЧ���ĺ��Ρ��ѷe�ͷֶ�D�ȡ����������N�µĈD�Σ�Ŀǰ��֪�����˿ڽ��������c�ܶȈD �ɷN��
2���y(t��ng)Ӌ������ȫ���^�̵�ݔ�������������ı����Ğ�����^�Ę��S�������Ҙ��S���ı��F(xi��n)�������ԕ��õ��M(j��n)һ������ߣ���������һЩ�µĹ��ܣ�����Ԍ��y(t��ng)Ӌ ���M(j��n)�������ڱ����кϲ�/ʡ������С�ݔ���ȡ����⣬���S�팢���Ա�ֱ�ӌ�(d��o)����PowerPoint�У��@Щ�o�ɶ��������Ñ���ʹ�á�
����Complex Samplesģ�K���ӽy(t��ng)Ӌ��ģ���ܡ�
Complex Samples��12����������ģ�K�����ڌ��F(xi��n)��(f��)�s��ӵ��O(sh��)Ӌ�������Լ�������(y��ng)�Ĕ�(sh��)��(j��)�M(j��n)������������(d��ng)�r��δ�ṩ�y(t��ng)Ӌ��ģ���ܡ���13���У��@�����кܴ�� ���^��һ�㾀��ģ�͌����������������(f��)�s���ģ�K�У��Ԍ��F(xi��n)����(f��)�s����о��и��N�B�m(x��)��׃���Ľ�ģ�A(y��)�y���ܣ����猦�Ј��{(di��o)���еĿ͑��M��Ȕ�(sh��)��(j��)�M(j��n)�н�ģ�� ���ڷ��(sh��)��(j��)��Logistic�ؚw�t������ϵ�y(t��ng)�����롣�@�ӣ�����һ�������(f��)�s�ij���о�������A�η���Ⱥ��ӣ����߸���(f��)�s��PPS��ӣ��о��߶��� ����ԓģ�K���p�ɵČ��F(xi��n)�ij���O(sh��)Ӌ���y(t��ng)Ӌ��������(f��)�s�y(t��ng)Ӌ��ģ�l(f��)�F(xi��n)Ӱ����ص����������^�̣��������ģ�͡����λؚwģ�͡�Logistic�ؚwģ�͵ȏ�(f��)�s �Ľy(t��ng)Ӌģ�Ͷ����Լ���ʹ�ã���������ʽ��������ȫ�S�C(j��)��Ӕ�(sh��)��(j��)�ķ��������]��ʲô��e�������A(y��)Ҋ��ԓģ�K���Ƴ����������M(j��n)����(n��i)����(f��)�s��ӕr�y(t��ng)Ӌ�Ɣ�ģ�� �����_��(y��ng)�á�
��������Classification Treeģ�K��
�@��ģ�K���H�Ͼ��nj���ǰ�Ϊ��l(f��)�е�SPSS AnswerTreeܛ�������M(j��n)��SPSSƽ�_���P�ߎ���ǰ���Լ��ľW(w��ng)վ�Ͻ�BSPSS 11���¹��ܕr������(j��ng)�ܼ��J��ָ��SPSSĿǰ�Įa(ch��n)Ʒ���^�ڷ�ɢ����(y��ng)��(d��ng)�Ѹ��N�����^��һ��Сܛ������AnswerTree��Sample Power�����ϵ�SPSS�Ȏׂ�ƽ�_��ȥ������SPSS��˾Ҳ���R�����@һ�c����AnswerTree�����ڴ˱����µ�һ�����ص����ϵĮa(ch��n)Ʒ��
Classification Treeģ�K���ڔ�(sh��)��(j��)�ھ��аl(f��)չ�����Ę�Y(ji��)��(g��u)ģ�͌����׃�����B�m(x��)׃���M(j��n)���A(y��)�y�����Է��㡢���ٵČ��ӱ��M(j��n)�м�(x��)�֣�������Ҫ�Ñ���̫��Ľy(t��ng)Ӌ���I(y��)֪�R��Ŀ ǰ���Ј���(x��)�ֺ͔�(sh��)��(j��)�ھ������^�V���đ�(y��ng)�á��F(xi��n)����֪ԓģ�K�ṩ��CHAID��Exhaustive CHAID��C&RT���N�㷨����AnswerTree���ṩ��QUEST�㷨�в��ܿ϶��Ƿ�����{�롣
���˷��������Ñ���ʹ�ã�Treeģ�K�ڲ�����ʽ�ϲ���ʹ��AnswerTree�е���?q��)���ʽ������SPSS�������_ʼ���õĽ���ʽ�x헿���Ԓ���ǣ� �����x헿�����ă�(n��i)���H���Ǻ�ԭ�ȵ���?q��)�����һ�µģ����⣬ģ�͵ĽY(ji��)��ݔ����Ȼ��AnswerTree�И�(bi��o)��(zh��n)�Ę��ΈD���@ʹ��AnswerTree���� �Ñ������ϲ���Ҫ���T�ČW(xu��)��(x��)���܉����ʹ��ԓģ�K��
���ژ�Y(ji��)��(g��u)ģ�͵ķ����wϵ�͂��y(t��ng)�Ľy(t��ng)Ӌ������ȫ��ͬ���Q(m��o)Ȼ������ܕ������x�߽y(t��ng)Ӌ�����wϵ�Ļ�y����ˣ����ξ����ĸ��̳̲�δ��Bԓģ�K�������ڸ��̵̳���һ���汾���Լ��P(gu��n)���Ј���(x��)�ֆ��}�Ľ̲��Ќ������Ԕ��(x��)��B��
�����õ�SPSSϵ�Юa(ch��n)Ʒ�����ԡ�
�S�������a(ch��n)Ʒ���IJ������ƣ�SPSS��˾�Įa(ch��n)Ʒ�wϵ�ѽ�(j��ng)��������������ͬ�a(ch��n)Ʒ�g�Ļ��a(b��)�ͼ�����Ҳ�ڲ�����Ը��M(j��n)����13���У�SPSSܛ���ѽ�(j��ng)���Ժ����� һЩ���µĮa(ch��n)Ʒ�ܺõ�������һ���γɸ��������Ľ�Q���������磬SPSS��SPSS Data Entry���°l(f��)����SPSS Text Analysis for Surveysһ����γ��ˌ��{(di��o)���о���������Q��������������SPSS Classification Treesģ�K��ʹ��SPSSܛ���������܉�ᘌ��Ј���(x��)�ֹ����ṩ���������ķ����wϵ��
SPSS17.0�����e�������P(gu��n)����
1�����_SPSSܛ��;�c��“�_ʼ”���o���p��“SPSS ”ܛ������(d��o)�딵(sh��)��(j��)���c�����Ͻ�“�ļ�”-----“���_”-----“��(sh��)��(j��)”�����x����Ĕ�(sh��)��(j��)�������spss��(sh��)��(j��)����ֱ�ӌ�(d��o)�룬����excel ��ʽ����Ҫ��“�ļ����”�����x��“excel��ʽ”
2���_ʼ����(sh��)��(j��)������
�ڹ��ߙ�̎���c����
“����”----”���P(gu��n)”----“�p׃��”�����D��ʾ���t�_ʼ�M(j��n)��׃�����x��
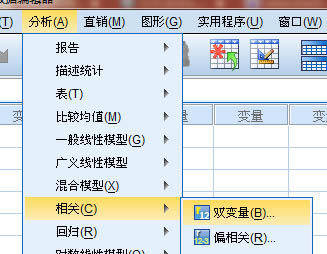
3����D����Ҫ�ȴ_��Ҫ������׃�������Ȍ��ɂ�׃������“׃��”���С�
�˕r����Ҫע�⣬Ҫ�����Ďׂ�׃����ֻ���x���ǎׂ�׃���������܌����е�׃���x�룻
��(d��ng)Ȼ������������Ƕ��е�׃����Ҳ����ͬ�r�����е�׃���x��
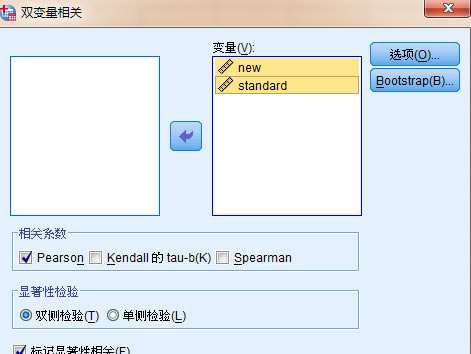
4��Ȼ���x����“���P(gu��n)ϵ��(sh��)”�����x��“Pearson”��
��飬�@��ăɂ�׃�����B�m(x��)�Ե�׃������˲���pearson ���P(gu��n)������
����ɂ����׃��������һ�����׃��һ���B�m(x��)�Ե�׃�����t������Spearman ���P(gu��n)����
5���x���׃��֮�������Ҫ����(sh��)��(j��)�M(j��n)��һ�������������߲鿴�����Դ��_���Ͻǵİ��o�����x��“�x�”�����D��ʾ
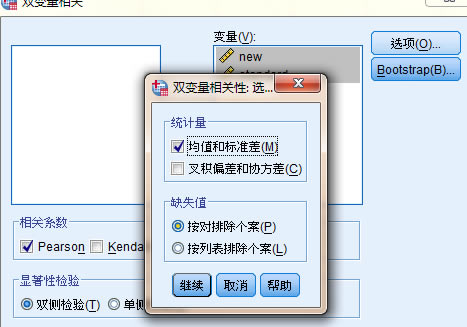
6���ַ�����Ҫ��ԭʼ��(sh��)��(j��)�M(j��n)�нy(t��ng)Ӌ�������������Ҫ�M(j��n)�������Է����������x���ֵ�͘�(bi��o)��(zh��n)����ψD��ʾ��mean ����ֵ���� sd ����(bi��o)��(zh��n)����քe����(sh��)��(j��)�Ĵ�С���xɢ�̶�����һ�������������c��“�_�����o”
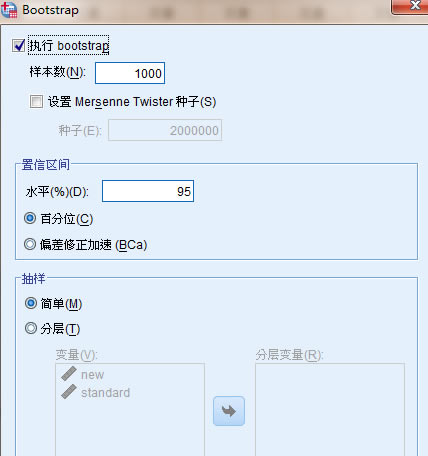
7�������Ҫ����(sh��)��(j��)�M(j��n)��ģ�M�������t�����x�����Ͻǵ�“bootsTrap”ģ�M���������_�����D��ʾ��
���Иӱ���(sh��)����Ҫģ�M�Ŀ����ĴΔ�(sh��)�������Լ����x������ķN�Ӕ�(sh��)�����_ʼģ�M�S�C(j��)��(sh��)�ֵ���ʼ�N�Ӕ�(sh��)��ͬ�ӿ������ж��x�����е����Ņ^(q��)�g��CI�� ���Y(ji��)���Ŀ��Ņ^(q��)�g
8���Γ��_������output�����п��Կ������Y(ji��)��������ʾ��
�Y(ji��)���o���ɂ�������һ���������Է����������µĵڶ����D����pearson ���P(gu��n)�����Y(ji��)�����һ���D��
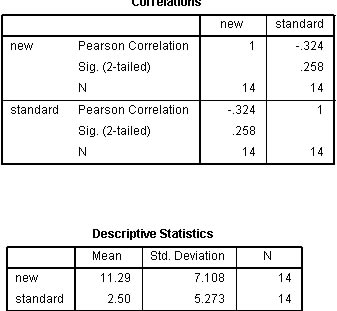
9��һ��Y(ji��)������(y��ng)ԓ�������ڶ����D�ı����x��
����mean��ʾ��ֵ����ɂ��B�m(x��)��׃���ľ���(sh��)���ڶ���ֵ��Std. Deviation ��ʾ��(bi��o)��(zh��n)���ԭʼ��(sh��)��(j��)�Ę�(bi��o)��(zh��n)��
10����һ���D��pearson correlations��������P(gu��n)ϵ��(sh��)��
����pearson correlation �����P(gu��n)ϵ��(sh��)
sig ��P ֵ��<0.05�����@�������x��
N ��ӱ���
SPSS17.0�����e����ô�O(sh��)������
���ȴ��_SPSS�����棬Ȼ���c�����ߙ��ϵ�“Edit”
Ȼ���x��“Option”
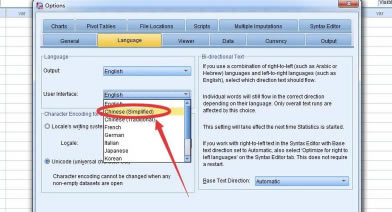
���_���x��“Language”
��“User Interface”һ�ں�����x��x���Z��
Ȼ���x��“Chinese Simplified”
Ȼ���c�������“OK”
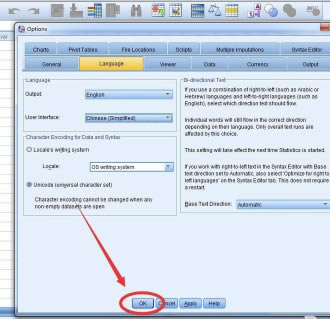
������ʾ��߀���x��“OK”
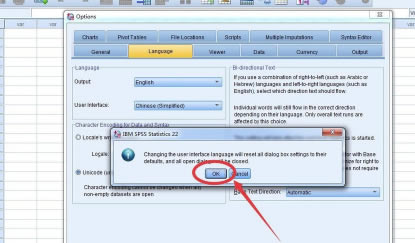
�@�Ӿ��O(sh��)�ó����Ľ�����
1�M���ƽ̌W(xu��)ͨ2.0-�M���ƽ̌W(xu��)ͨ2.0���d v5......
2step7 microwin-���T��PLC S7......
3�ٶȾW(w��ng)�P��ˬ����������-�W(w��ng)�P����-�ٶȾW(w��ng)�P��ˬ��......
4360��ȫ�g�[��-�g�[��-360��ȫ�g�[�����d ......
5�ȸ�g�[�� XP��-�ȸ�g�[�� XP��-�ȸ�g�[......
6Kittenblock�ؑc�������ð�-�C(j��)���˾���......
7seo�������(�������) -SEO��會�(y��u)������......
8С���\��ˢ����(sh��)����-С���\��ˢ����(sh��)�������d v2......
1����\��GHOST���bϵ�y(t��ng),��������\���R���b�C(j��)
2Ů����ɶ���^��ã��m��Ů���\�õ����^��_��
3���Ľ�����ΰ��bghostxpϵ�y(t��ng)
4�o�����(bi��o)�p�ĵĎNԭ�� �Լ�̎������
5Windows��������Win10ʧ����ʾ0x80...
6����Windows10 1607�汾�ľ��w�O(sh��)�÷�...
7win10��X�桶ֲ����(zh��n)��ʬ���W�˵�̎���k��
82018������^����ɶ��2018���Ů��...