

- SPSS�����ؘ�_SPSS�D�����Д���
- SPSS�l�ʅ^���c�����^�ֵIJ�ͬ�cԔ���f��
- SPSS�ĆΘӱ��������ӱ����䌦�ӱ�T�z���
- ���ͨ�^SPSS��헷ֲ��z��C�aƷ�ĺϸ�
- SPSS���¾��a��SPSS�ԄӾ��a���ɣ�
- ��Α���SPSS�Θӱ�T�zSPSS�z��
- ���ͨ�^SPSS�����ӱ�T�z�^�փɽM������
- SPSS���ָ���^�ַ���֮�x��
- SPSS�ә������đ��ý�B
- ��Α���SPSSӋ����׃�����ɣ��ھ��¶���
- ��Α���SPSS������ֵ��Ӌ������
- SPSS���¾��a֮���a����ͬ��ͬ��׃��

SPSS�����ؘ�_SPSS��Ό��x�������ؽM��׃��
�l���r�g:2025-05-04 ����Դ:xp���dվ �g�[:
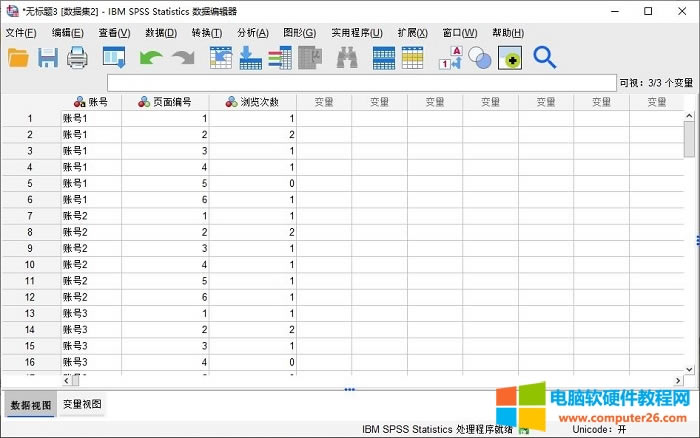
| SPSS��IBM��˾��Ʒ�����ṩ�˰��������ԽyӋ���Ɣ��ԽyӋ�����ӷ�������������ؚw�����ȶ�N�yӋ�������ܣ��������ı��������C���W���㷨����������ģ�͵ȡ�SPSS�Ľ����Ѻã����ڲ������܉���ُĔ�������ȡ���õĶ���ͷ������V�������ڽ������������t�W���Ј����˿ڡ����U�ȶ����о��I��Ҳ���ڮaƷ�|�����ơ����n���������ճ��yӋ����ȡ� IBM SPSS Statistics�Ĕ����ؘ����ܣ�Ҳ���Q�锵���ؽM�������ˌ��x��׃���ؽM�邀�������x�������ؽM��׃���c׃�Q���Д������������D�ã��Ĺ��ܡ� �����У����M��“���x�������ؽM��׃��”�Ĺ����v�⡣���҂�Ҫ�M�зֽM׃���ķ����r������Ҫ�������M�����D�Q��׃���M����������һ�㾀��ģ�ͷ����еĆ�׃������׃���ͷ���ɷ֡� һ�����_�����ļ� ���ȣ���D1��ʾ�����_�����M��͵Ĕ�������ǰ����չʾ�˂����ڲ�ͬ����еĞg�[�Δ�����Ҫ��“��澎̖”�ؽM����׃����
�D1�����_�����ļ� ����ʹ�Ô����ؘ����� ��D2��ʾ�����_�����ˆ��е��ؘ��������ܡ�
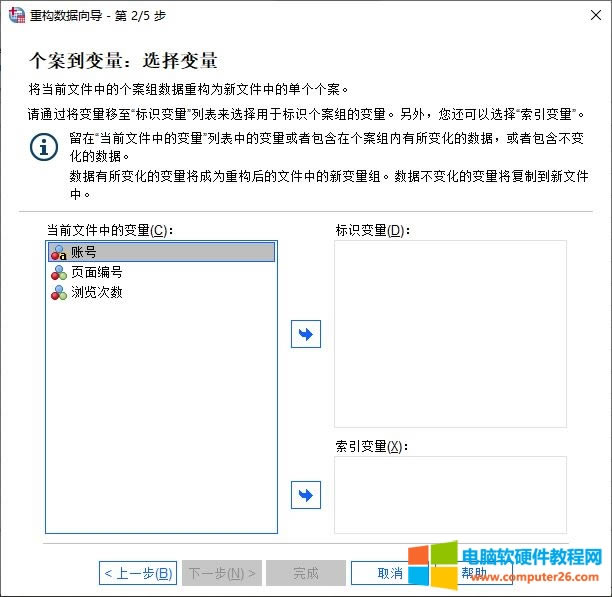
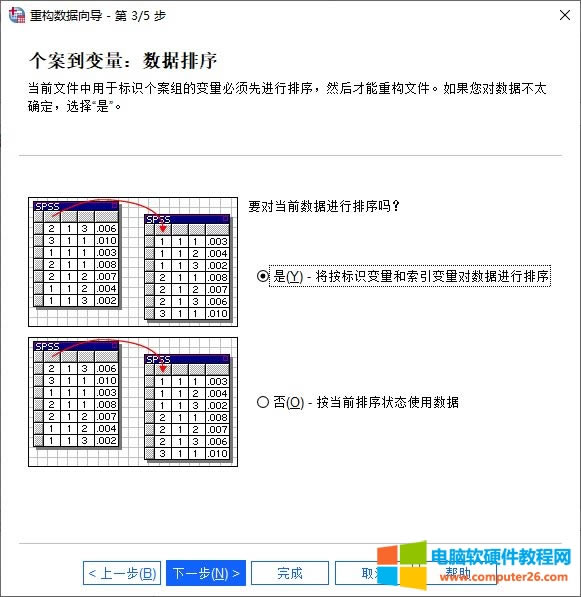
�D2�������ؘ����� �����x�����ؘ���׃�� ��D3��ʾ���ڴ��_���ؘ��������У������xȡ�����ؘ��ķ������҂��x��“���x�������ؘ���׃��”�x헡�
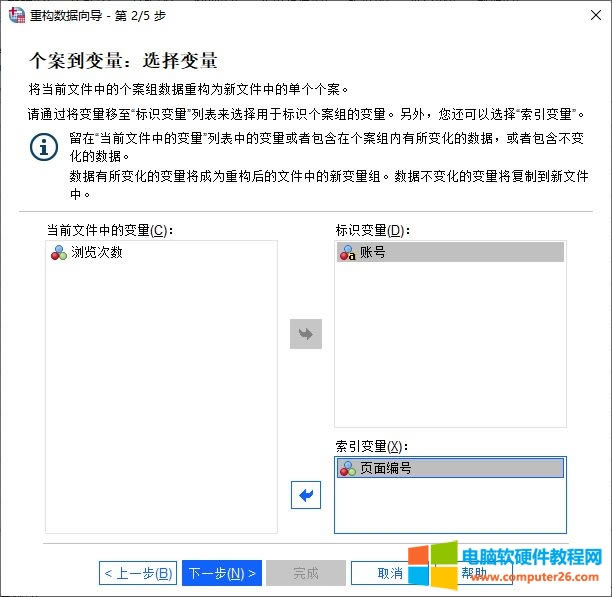
�D3���ؘ������� �������҂���Ҫ�M�б��^�P�I��һ��—�x��׃�������е�׃�����x���£� 1.���R׃�������Á��R�e������׃�������籾���е�“�~̖”׃�����������R�e������ 2.����׃������ǰ���������ڄ������еĵ�׃������׃�����Ӟ�����׃����ϵ�y����ԓ׃���е�׃��ֵ�ؽM������׃�������籾���е�“��澎̖”׃���� 3.��ǰ�ļ��е�׃�������l��׃����׃����ԓ׃���Ĕ������ܕ����ؘ�����׃��
�D4���x��׃�� ������ǰ�������ؘ���Ŀ�ģ�����“�~̖”�Ă����M�����ؘ������������D5��ʾ���茢“�~̖”�O�Þ���R׃������“��澎̖”�O�Þ�����׃��������“�g�[�Δ�”�鮔ǰ�ļ��е�׃����
�D5���O��׃�� �������O�Ô���������ʽ���ɰ����R׃���c����׃���M������Ҳ���x���ծ�ǰ�����B����
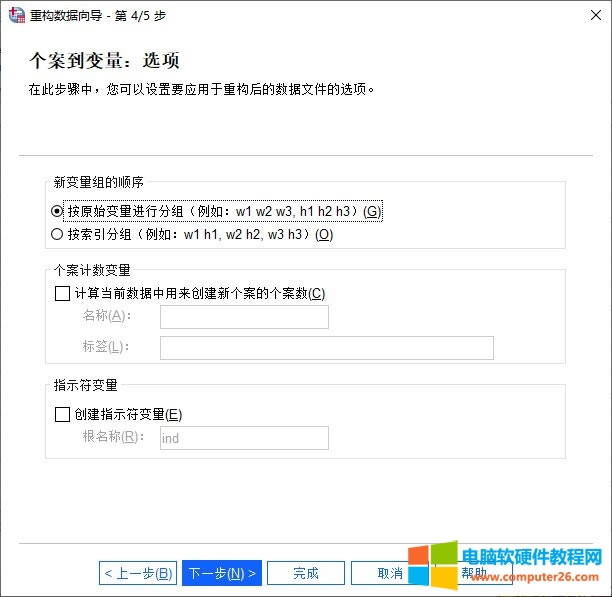
�D6�������x� ����������ؘ���Ĕ����ļ��x��M���O�ã� 1.�O����׃���M����ɰ�ԭʼ׃���ֽM��������׃��1��������׃��2����w1 w2 w3,h1 h2 h3��������׃���ֽM������׃������һ������,��w1 h1,w2 h2,�� 2.���ӂ���Ӌ��׃�� 3.����ָʾ��׃��,��ʹ������׃�����µĔ����ļ��Є���ָʾ��׃��,��������׃����ÿ��Ψһֵ����һ����׃����
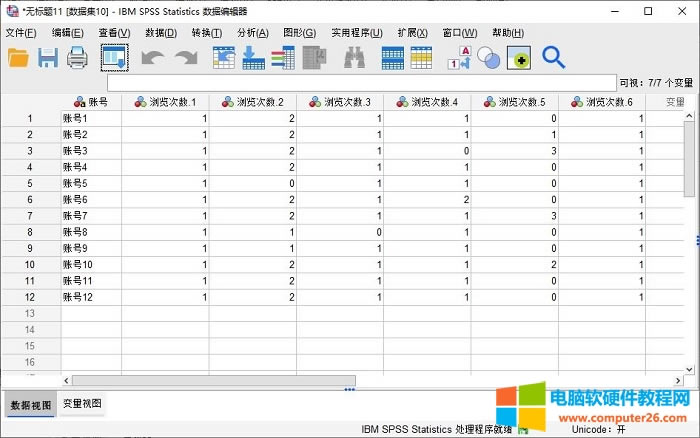
�D7���ؘ����ļ����x� ��ɔ����ؘ��O�ú��҂������x�������ؘ��������桢���㷨�����ؘ�������
�D8�������㷨�������ؘ� ��ɔ����غ���D8��ʾ������չ�F���ڲ�ͬ�����²�ͬ����׃���Ğg�[�Δ���
�D9����ɔ������ؘ� �������S����Ӱ푵Ĉ��s־��SPSS�o���˸߶ȵ��u�r�� |
���P����
Windowsϵ�y�̳̙�Ŀ
��̳�����
ϵ�y���T�̳�
�����Tϵ�y������