
- SPSS��(sh��)��(j��)�ؘ�(g��u)_SPSS��Ό��x�������ؽM
- SPSS��(sh��)��(j��)�ؘ�(g��u)_SPSS�D(zhu��n)�����Д�(sh��)��(j��)
- SPSS�l�ʅ^(q��)���c�����^(q��)�ֵIJ�ͬ�cԔ���f��
- SPSS�ĆΘӱ��������ӱ����䌦�ӱ�T�z���
- ���ͨ�^SPSS��헷ֲ��z��C�a(ch��n)Ʒ�ĺϸ�
- SPSS���¾��a��SPSS�ԄӾ��a���ɣ�
- ��Α�(y��ng)��SPSS�Θӱ�T�zSPSS�z��
- ���ͨ�^SPSS�����ӱ�T�z�^(q��)�փɽM������
- SPSS���ָ���^(q��)�ַ���֮�x��
- SPSS�ә�(qu��n)�����đ�(y��ng)�ý�B
- ��Α�(y��ng)��SPSSӋ����׃�����ɣ��ھ��¶���
- ��Α�(y��ng)��SPSS������ֵ��Ӌ��(sh��)����
���]ϵ�y(t��ng)���d��� ����Windows10ϵ�y(t��ng)���d ����Windows7ϵ�y(t��ng)���d xpϵ�y(t��ng)���d ��X��˾W(w��ng)indows7 64λ�b�C�f�ܰ����d

SPSS��(sh��)��(j��)�ؘ�(g��u)_SPSS��Ό��x��׃���ؽM�邀��
�l(f��)���r�g:2025-05-04 ����Դ:xp���dվ �g�[:
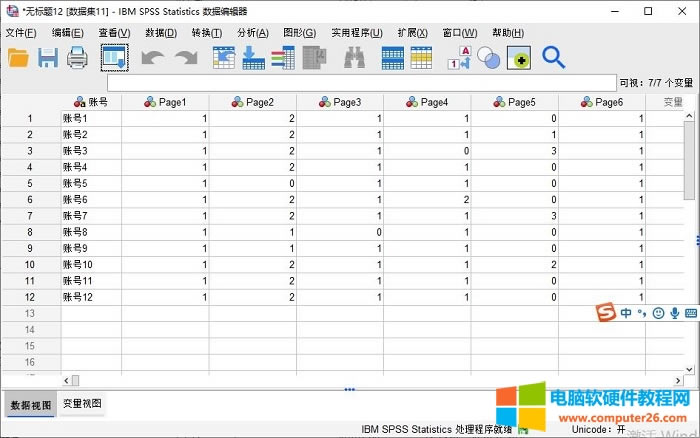
| SPSS��IBM��˾��Ʒ�����ṩ�˰��������Խy(t��ng)Ӌ���Ɣ��Խy(t��ng)Ӌ�����ӷ�������������ؚw�����ȶ�N�y(t��ng)Ӌ�������ܣ��������ı��������C���W���㷨����(sh��)��(j��)����ģ�͵ȡ�SPSS�Ľ����Ѻã����ڲ������܉���ُĔ�(sh��)��(j��)����ȡ���õĶ���ͷ������V����(y��ng)���ڽ������������t(y��)�W���Ј����˿ڡ����U�ȶ����о��I(l��ng)��Ҳ���ڮa(ch��n)Ʒ�|(zh��)�����ơ����n���������ճ��y(t��ng)Ӌ����ȡ� IBM SPSS Statistics�Ĕ�(sh��)��(j��)�ؘ�(g��u)���ܣ�Ҳ���Q�锵(sh��)��(j��)�ؽM�������ˌ��x��׃���ؽM�邀�������x�������ؽM��׃���c׃�Q���Д�(sh��)��(j��)������(sh��)��(j��)�D(zhu��n)�ã��Ĺ��ܡ� ��ʲôҪ�M�Д�(sh��)��(j��)�ؽM���@�����һЩ��������������Ҫ���Â����M��׃���M�Ĕ�(sh��)��(j��)����������ˣ���Ҫͨ�^�ؽM�ķ�ʽ�D(zhu��n)�Q��(sh��)��(j��)�����Č������c��B��Ό��x��׃���ؽM�邀���� һ�����_��(sh��)��(j��)�ļ� ���ȣ���D1��ʾ�����_׃���M��͵Ĕ�(sh��)��(j��)��ԓ��(sh��)��(j��)ӛ���ÿ���~̖�ڲ�ͬ���Ğg�[�Δ�(sh��)��
�D1��׃���M��(sh��)��(j��) ����ʹ�Ô�(sh��)��(j��)�ؘ�(g��u)���� ��������D2��ʾ�����_��(sh��)��(j��)�ˆ��е��ؘ�(g��u)�x헡�
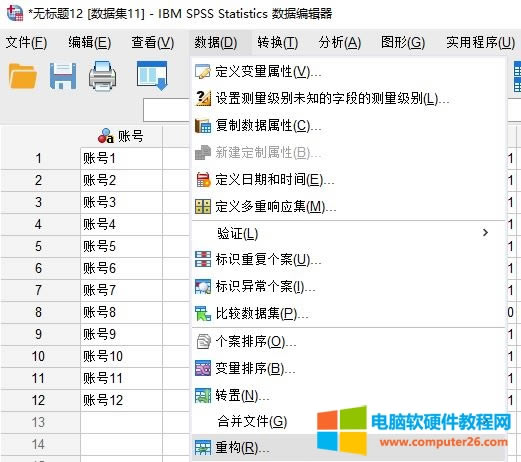
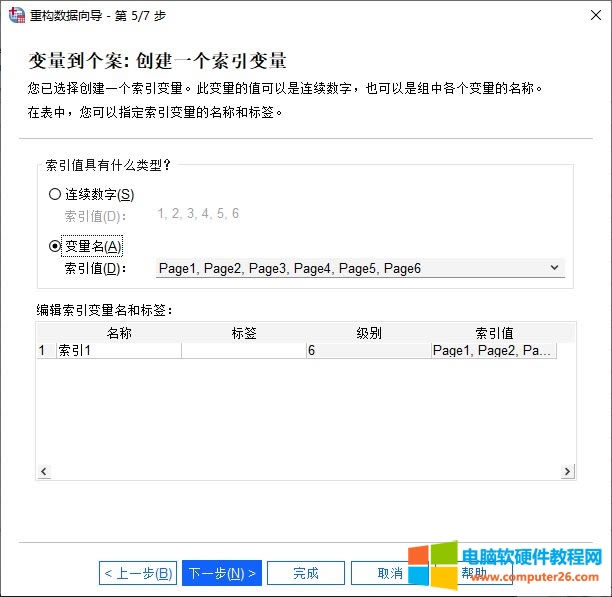
�D2����(sh��)��(j��)�ؘ�(g��u)���� �����x���x��׃���ؘ�(g��u)�邀�� ��D3��ʾ���ڴ��_���ؘ�(g��u)��(sh��)��(j��)��?q��)��У������xȡ��(sh��)��(j��)�ؘ�(g��u)�ķ������҂��x��“���x��׃���ؘ�(g��u)�邀��”�x헡�
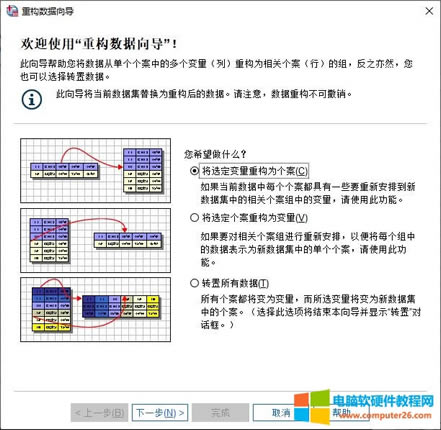
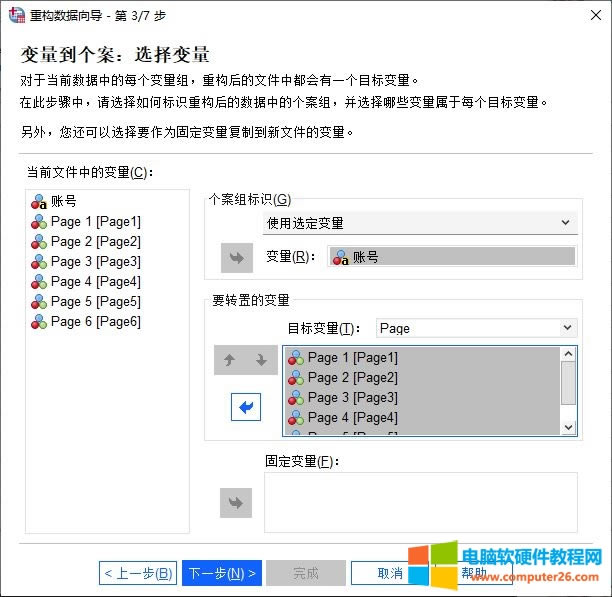
�������͕��������^�P(gu��n)�I�IJ��E-�x��׃�����҂�����������M��׃���x�� 1.��ǰ�ļ��е�׃��������ǰ��(sh��)��(j��)������������׃���� 2.�����M���R���������R�e������׃�������籾���е�“�~̖”׃���������邀���M���R���R�e��ͬ�Ă����� 3.Ŀ��׃�������ؘ�(g��u)����F(xi��n)��׃������Ҫ�����ؘ�(g��u)��׃�����Ӟ�“Ҫ�D(zhu��n)�õ�׃��”��Ȼ���ٞ��@Щ�D(zhu��n)�õ�׃����(chu��ng)��һ��Ŀ��׃�����f���@Щ�D(zhu��n)��׃���������������ڱ����У���“Page1-6”��׃�����Ӟ�Ҫ�D(zhu��n)�õ�׃����Ȼ��(chu��ng)��һ������“Page”��Ŀ��׃���� 4.�̶�׃���������ֲ�׃��׃���������Пo�̶�׃���� ��D4��ʾ���҂��ѽ�(j��ng)����׃���Č��������׃�����x��
�D4���x��׃�� ��������Ҫ��(chu��ng)������׃���� ����(chu��ng)����Ŀ��׃���Ĕ�(sh��)ֵ�چ������Е��ж���׃�����F(xi��n)�r������Ҫ��(chu��ng)������׃���R�e�������У��҂�ʹ�õ��dž����ӵ�Ŀ��׃���������x��(chu��ng)��“һ��”����׃����
�D5����(chu��ng)������׃�� Ȼ�����O(sh��)������ֵ����ͣ������R�e��ͬ����Ŀ��׃������(y��ng)����ֵ�ĺ��x����D6��ʾ����ʹ���B�m(x��)��(sh��)�ֻ�׃�����M���R�e��
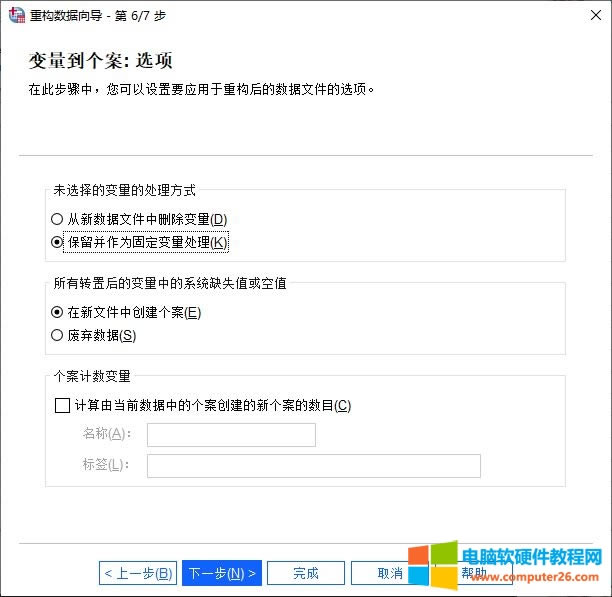
�D6���O(sh��)������ֵ��� �����(y��ng)�����ؘ�(g��u)�Ĕ�(sh��)��(j��)�ļ��x��M���O(sh��)�ã� 1. ��δ�x���׃����̎����ʽ���h��������̶�׃�� 2. �D(zhu��n)�ú��׃���е�ϵ�y(t��ng)ȱʧֵ����ƣ���(chu��ng)��������U����(sh��)��(j��) 3. ��(chu��ng)��Ӌ��(sh��)׃��
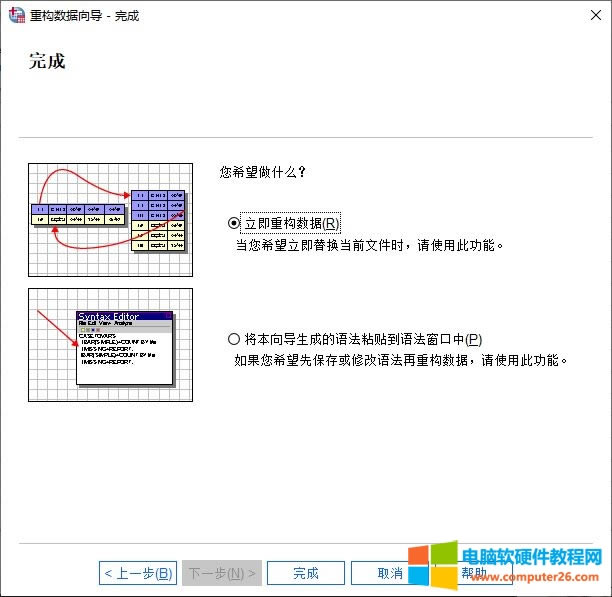
�D7���O(sh��)���ؘ�(g��u)��Ĕ�(sh��)��(j��)�ļ� ��ɔ�(sh��)��(j��)�ؘ�(g��u)�O(sh��)�ú��҂������x�������ؘ�(g��u)��(sh��)��(j��)���桢���㷨�����ؘ�(g��u)��(sh��)��(j��)��
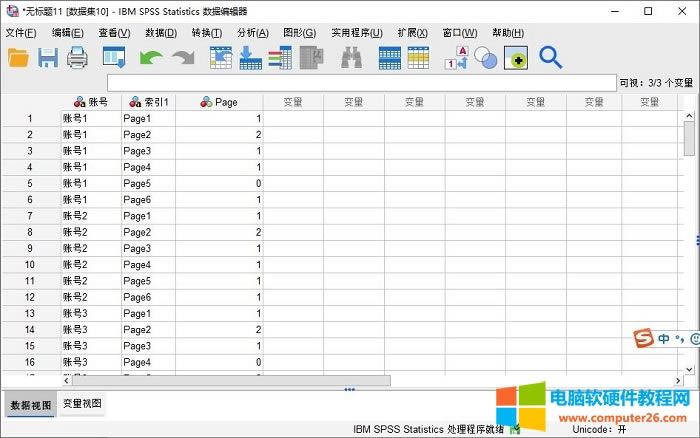
�D8�������ؘ�(g��u)��(sh��)��(j��) ��ɔ�(sh��)��(j��)�ؘ�(g��u)���Կ����~̖1�а�����6�N����ֵ׃��������(y��ng)ÿһ������ֵ׃�������䌦��(y��ng)��“Page”��(sh��)��
�D9����ɔ�(sh��)��(j��)���ؘ�(g��u) �������S����Ӱ푵Ĉ��s־��SPSS�o���˸߶ȵ��u�r�� |
���P(gu��n)����
Windowsϵ�y(t��ng)�̳̙�Ŀ
��̳�����
ϵ�y(t��ng)���T�̳�
1����\��GHOST���bϵ�y(t��ng),��������\���R���b�C
2ϵ�y(t��ng)֮�ҽ����A�T�Pӛ���A(y��)�bWindows10��w...
3ϵ�y(t��ng)֮��һ�IU�P���bwindows7ϵ�y(t��ng)�D��Ԕ��...
4Ů����ɶ���^��ã��m��Ů���\�õ����^��_��
5���Ľ�����ΰ��bghostxpϵ�y(t��ng)
7Windows��������Win10ʧ����ʾ0x80...
8����Windows10 1607�汾�ľ��w�O(sh��)�÷�...
�����Tϵ�y(t��ng)������