
- Excel��Ԫ���Ԅ���侎̖�����С�18λ�L
- Excel�Ԅ���������cÿ���f��3��犵ĕr�g
- Excel���c�����ÿ���I���x��c��ֲ�Ѹ��
- Excel�ÿ���I�c�x���ƽ��ֵ������һ�Ό�
- һ������Excel�����ˆ�������c��θ��h
- Excel����Ļ����O�ÈD��ʹ�ý̳̣����w��
- excelб�����^�����������D��ʹ�ý̳�
- excel�����ӡ������h�����@ʾ/�[����ע
- Excel��ӡ֪�R����
- ����Ԅ�ͬ��ˢ���ⲿ�� Excel (.xl
- excel����С���c��2λ��ʽ��excel��
- Excel If�����Ηl���c��Ƕ��And/

Excel��ֆ�Ԫ���c�÷����c��ʽ��һ�Ѓ��ݲ�֞���л�����
�l���r�g:2025-03-15 ����Դ:xp���dվ �g�[:
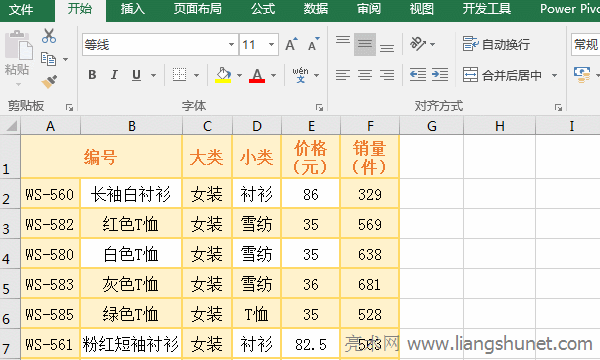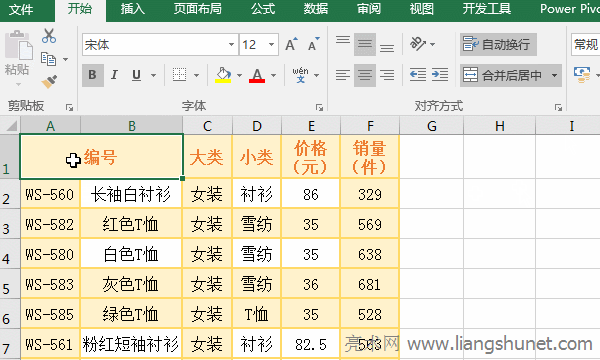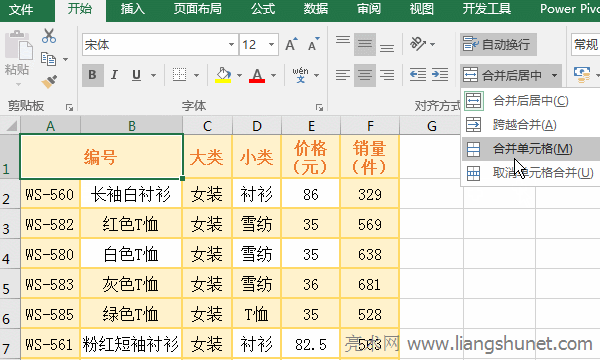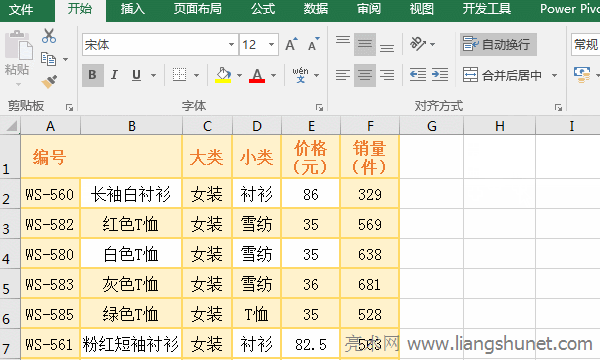
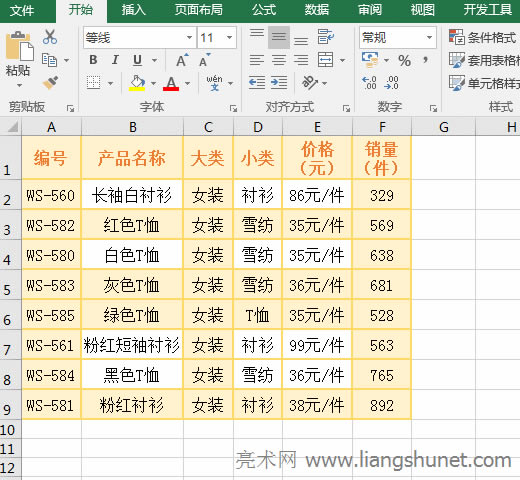
| �k��ܛ����ָ�����M������̎���������������ß�Ƭ�������D�ΈD��̎�������Δ������̎���ȷ��湤����ܛ����Ŀǰ�k��ܛ�������������λ������ܼ����ȷ���lչ���k��ܛ���đ��÷����V��������yӋ��С�����hӛ䛣����ֻ����k�����x���_�k��ܛ���Ķ����f�������⣬�����õ�������գ������õĶ���ϵ�y����I�õąfͬ�k��ܛ�����@Щ�������k��ܛ���� �� Excel �У���ֆ�Ԫ���ЃɷN������һ�N�� Excel �ṩ���x헲�֣���һ�N�ÿ���I��֡�Excel��ֆ�Ԫ��ֻ�ܰѺϲ���Ć�Ԫ���֣����ܰ�һ���]�кϲ��^�Ī�����Ԫ���֞�ɂ���ɂ����ϡ� �ھ� Excel �����^���У�����ֆ�Ԫ���⣬����߀��������һ����Ԫ����ݲ�ֵ��ɂ��������Ԫ����һ�в�֞���л��������������С��oՓ�Dz�ֆ�Ԫ�����߀�Dz���У��������÷��з���ʽ����������������@�ָ�����ֲ��������÷��з��������ĸ�����c�h�ֻ��s�����÷��в�֣������ù�ʽ���� һ��Excel��ֆ�Ԫ����һ������һ���x�� �x�д���ֆ�Ԫ������ A1 �� B1���x��“�_ʼ”�x헿����Γ�“�ϲ������”��߅�ĺ�ɫС�����ǣ��ڏ����IJˆ����x��“ȡ���ϲ���Ԫ��”���t A1 �� B1 �����·֞�ɂ���Ԫ�����^�̲��E����D1��ʾ��
�D1 ��ʾ��Excel��ֆ�Ԫ���� Word �����O�ò�֞�ׂ�����ֻ�������ϲ���Ԫ��Ĕ�Ŀ��֣�����ϲ���Ԫ��r�ǰуɂ���Ԫ��ϲ���һ����Ԫ�t��֕r�ԄӲ�֞�ɣ���������Ԫ��ϲ���һ����Ԫ��֕r�ԄӲ�֞��������������Դ���ơ� ������������������I�� Excel��ֆ�Ԫ�����I�� Alt + H + M + U�����������飺�x�� A1:C1 ��Ԫ��ס Alt �I����һ�� H����һ�� M���ٰ�һ�� U���t A1:C1 �����²�֞�������Ԫ�����^�̲��E����D2��ʾ��
�D2 ��ʾ�����ڲ�ֺ�Ć�Ԫ��ȱ��߅�����Կ�����������Ԫ����Ȼ��һ�����������ѽ��Ƶ��� A1 ��Ԫ�����Ҫ�o��ֺ�Ć�Ԫ�����߅���� Ctrl + 1 �M���I���x��“߅��”�x헿����c����߅���ϵĈD�ˣ��Γ�“�_��”���ɡ� ����Excel��ֆ�Ԫ�������һ����“����”��“�ָ���”��� 1������Ҫ�ѷ��b����“��̖”�в�֞���С����I�ڶ���픲��� B���ڏ����IJˆ����x��“����”���t�ڵ�һ���c�ڶ���֮�g����һ�У��Γ� A �x�� A �У��x��“����”�x헿����Γ�“����”�����_“�ı�������”���ڣ�“Ո�x������m���ļ����”�x��“�ָ���̖”���Γ�“��һ��”�����x“����”��������߅ݔ�� -���Γ�“��һ��”���Γ�“���”���t��һ�б��Ķ̙M̎��֞���У������^�̲��E����D3��ʾ��
�D3 2���IJ�ֽY�����Կ�������ֺ��ַ���-���]���ˣ������һ���������ַ�Ҳ��һ�ӡ����⣬“�ı�������”���ṩ���ķN��ַ����քe��“Tab�I����̖����̖�Ϳո�”�����Ҫ��ֵă���������ij����̖�Ӷ࣬�����x������ַ��� ��������“����”��“�̶�����”��֣����Բ�֞���л��������� 1�����I F ����ĸ F���ڏ����IJˆ����x��“����”���� E ����߅����һ�У��x�� E �У��x��“����”�x헿����Γ�“����”�����_“�ı�������”���ڣ�“Ո�x������m���ļ����”�x��“�̶�����”���Γ�“��һ��”��������Ƶ�Ҫ���̎�����Ę˳�̎���Γ�һ�£��t���Fһ��ָ��˳ߵļ��^��������һ�c��ʹ���^ǡ��̎��Ҫ���̎���Γ�“��һ��”������֞�ăɲ�����߅���Ϻ�ɫ�ı��������ԓ��˴_�J�Ƿ�Ҫ�����ˣ��������Ҫ�Γ�“���”�����������Ҫ���ԆΓ�“��һ��”�^�m�{�����@���ѽ���ֺ��ˣ��Γ�“���”���tһ�б���֞���У������^�̲��E����D4��ʾ��
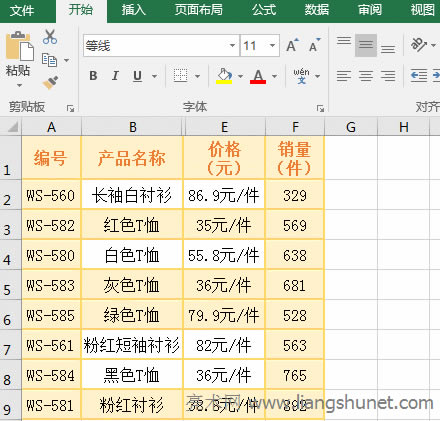
�D4 2�����Ҫ��֞����У���“�ı������”���ڵ�“�˳�̎”���Γ�һ�ξ͕��ֳ��Fһ�����^���������Դ���ơ�“�̶�����”����m���ڔ����ֲ������R���С� �������ù�ʽ��֣��m���ڔ����ֲ���������� 1������������@�ַ��Č��� ��1������Ҫ�уr���в�֞锵�����c��λ�С��x�� G2 ��Ԫ�ѹ�ʽ =LEFT(E2,FIND("Ԫ",E2)-1) ���Ƶ� G2������܇������ 86.9���tE2 �r��Ĕ��ֱ���ֵ� G2��������Ƶ� G2 ���½ǵĆ�Ԫ�������ϣ���ס���I�������ϣ��t�r����������Ԫ��Ĕ���Ҳ����ֵ� G �Ќ����Ć�Ԫ�ѹ�ʽ =MID(E2,FIND("Ԫ",E2),3) ���Ƶ� H2 ��Ԫ����܇���t E2 �r��Ć�λ����ֵ� H2��ͬ���������ϵķ������уr����������Ԫ��Ć�λ��ֵ� H �Ќ����Ć�Ԫ�����^�̲��E����D5��ʾ��
�D5 ��2����ʽ�f���� A��Left�����ı��_ʽ�飺=LEFT(Text, [Num_Chars])��Text ��Դ�ı���Num_Chars ��Ҫ��ȡ���ַ�������ʡ�ԣ� Find�����ı��_ʽ�飺=FIND(Find_Text, Within_Text, [Start_Num])��Find_Text ��Ҫ�ҵ��ı���Within_Text ��Դ�ı���Start_Num ������_ʼλ�ã���ʡ�ԡ� Mid�����ı��_ʽ�飺=MID(Text, Start_Num, Num_Chars)��Text ��Դ�ı���Start_Num ���_ʼ��ȡλ�ã�Num_Chars ���ȡ�ַ����� B����ʽ =LEFT(E2,FIND("Ԫ",E2)-1) �� FIND("Ԫ",E2)-1 �ҳ�“Ԫ”���ı��е�λ�ã�����Ҫ��ȡ�����֣�����Ҫ�p 1��Ȼ���� Left������ȡ���֡� C����ʽ =MID(E2,FIND("Ԫ",E2),3) �� FIND("Ԫ",E2) �ҳ�Ҫ��ȡ���_ʼλ�ã�Ȼ���� Mid�������ҳ����_ʼλ�����ȡ 3 ���ַ��� 2����ֻ��s���ַ������� ��1������Ҫ�����“��ĸ���� + �h�� + ����”�M�ɵ��ַ��������С��x�� B1 ��Ԫ�ѹ�ʽ��
�D6 ��2����ֺ���Ĕ��ֲ��֡��x�� D1 ��Ԫ�ѹ�ʽ��
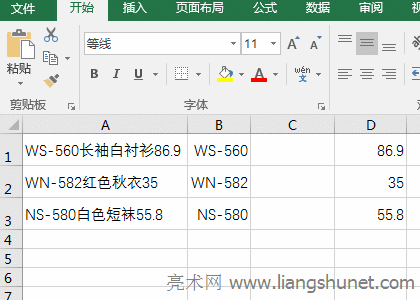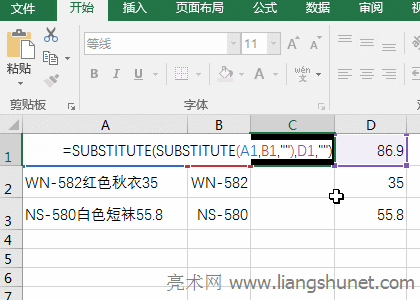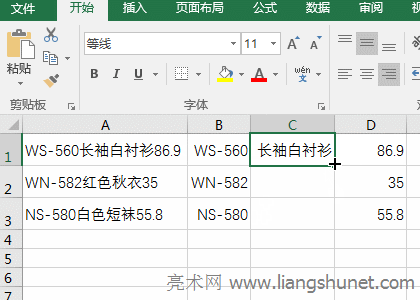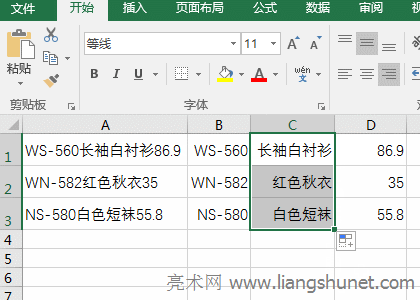
�D7 ��3��������g�ĝh�ֲ��֡��x�� C1 ��Ԫ�ѹ�ʽ =SUBSTITUTE(SUBSTITUTE(A1,B1,""),D1,"") ���Ƶ� C1������܇���� A1 �������g��“�h�ֲ���”��ֵ� C1��ͬ���������ϵķ������� A2 �� A3 �ă��ݵ����g“�h�ֲ���”�քe��ֵ� C2 �� C3�������^�̲��E����D8��ʾ��
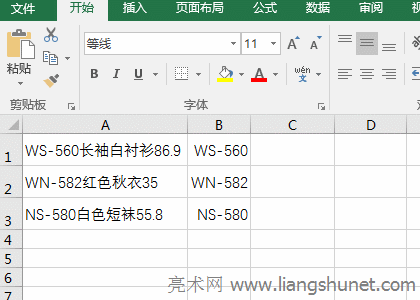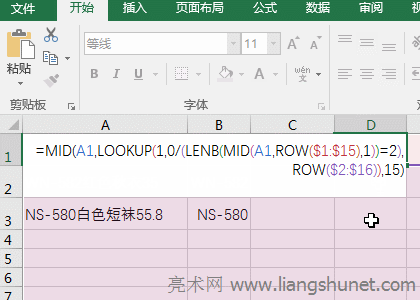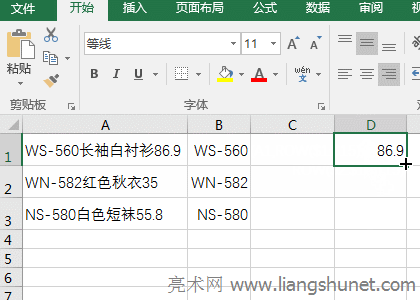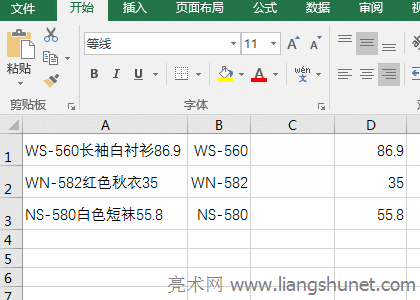
�D8 ��4����ʽ�f���� A�������߅“��ĸ����”�Ĺ�ʽ�� �� ���� MID(A1,ROW($1:$15),1) �� A1 �е�ÿ�����ֲ���_���Y���飺 {"W";"S";"-";"560";"�L";"��";"��";"�r";"��";"8";"6";".";"9"}������ô�����@�����M�ģ�ROW($1:$15) ����һ�� 1 �� 15 �Ĕ��M��15 ��ʾ A1 �е��ַ����������� {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15}��Mid ÿ�ΏĔ��M��ȡ��һ��Ԫ�������_ʼ��ȡ��������ÿ�ν�ȡһ���ַ������磺��һ�ΏĔ��M��ȡ�� 1�����ĵ�һλ�_ʼ��ȡ����ȡһ���ַ������� "W"���ڶ��ΏĔ��M��ȡ�� 2�����ĵڶ�λ�_ʼ��ȡ����ȡһ���ַ������� "S"���Դ����ֱ��ȡ�ꔵ�M�е�����Ԫ�ء� �� �t LENB(MID(A1,ROW($1:$15),1)=1 ׃�� LENB({"W";"S";"-";"560";"�L";"��";"��";"�r";"��";"8";"6";".";"9"})=1��LenB ���ΏĔ��M��ȡ��ÿһ��Ԫ�أ��������������ֹ������Y��׃�� {1,1,1,1,1,1,2,2,2,2,2,1,1,1,1}=1�����ÿ����ĸ���ֵ��ֹ����� 1��ÿ���h�ֵ��ֹ����� 2��Ȼ����ȡ���M�е�ÿһ��Ԫ���c 1 ���^��������� 1���t���� True����t���� False�����{True,True,True,True,True,True,False,False,False,False,False,True,True,True,True}��
�� LENB(MID(A1,ROW($2:$16),1))=2 �c LENB(MID(A1,ROW($1:$15),1))=1 ��һ�ӵĵ���������ͬ�������ĵڶ�λ�_ʼ�� A1 �е�ÿ�����ֲ���_��Ҳ�����ᗉ��һ���֣���ʲôҪ�@�Ӳ�֣�LENB(MID(A1,ROW($2:$16),1))=2 ���صĽY���� {1,1,1,1,1,2,2,2,2,2,1,1,1,1,0}=2��Ȼ��ȡ�����M�е�ÿ��Ԫ���c 2 ���^�������ȣ��t���� True����t���� False����ؽY��{False,False,False,False,False,True,True,True,True,True,False,False,False,False,False}�� �� ���ˣ�(LENB(MID(A1,ROW($1:$15),1))=1)*(LENB(MID(A1,ROW($2:$16),1))=2) ׃�飺 �� ��ʽ׃�� =LEFT(A1,LOOKUP(1,0/({0,0,0,0,0,1,0,0,0,0,0,0,0,0,0}),ROW($1:$15)))�������� 0 ���Ԕ��M�е�ÿһ��Ԫ�أ���ʽ׃�飺 ��ʽ׃�飺 �� ��ʽ׃�飺=LEFT(A1,6)������� Left ����߅��ȡ A1 �е�������߅ 6 ���ַ����� WS-560��
B�������߅���ֵĹ�ʽ��=MID(A1,LOOKUP(1,0/(LENB(MID(A1,ROW($1:$15),1))=2),ROW($2:$16)),15) �� LENB(MID(A1,ROW($1:$15),1))=2 ���ص�ֵ�����ѽ������^���Y����{False,False,False,False,False,False,True,True,True,True,True,False,False,False,False}�������� 0 ���Ԕ��M�е�ÿ��Ԫ�أ����ؽY���� {#DIV/0!,#DIV/0!,#DIV/0!,#DIV/0!,#DIV/0!,#DIV/0!,0,0,0,0,0,#DIV/0!,#DIV/0!,#DIV/0!,#DIV/0!}�� �� ROW($2:$16) ���� 2 �� 16 �Ĕ��M���� {2,3,4,5,6,7,8,9,10,11,12,13,14,15,16}���t��ʽ׃�飺 �� ��ʽ׃�飺=MID(A1,12,15)������� Mid �� A1 �е����֏ĵ� 12 �_ʼ��ȡ������ȡ 15 �ַ������� A1 �е����ֺ���Ĕ��� 86.9����ʾ��Mid�������ָ���Ľ�ȡ�ַ��������ı��L�ȣ�ֻ��ȡ��ĩβ�� C��������g�IJ��ֹ�ʽ��=SUBSTITUTE(SUBSTITUTE(A1,B1,""),D1,"") ��ʽ�Ƀɂ� SubStitute����Ƕ�M�ɣ������ SUBSTITUTE(A1,B1,"") ������Q B1 �ă��ݣ�����“��”��Q A1 �е� B1���� WS-560 ��Q“WS-560�L����r��86.9”��“WS-560”��������� SubStitute ������Q D1 �ă��ݣ��� SUBSTITUTE(A1,B1,"") ����Q����ʽ׃�飺=SUBSTITUTE("�L����r��86.9",D1,"")������“��”��Q D1 �����֣�86.9�������“�L����r��”�� ��ʾ����ʽ =SUBSTITUTE(SUBSTITUTE(A1,B1,""),D1,"")����ʡ�� ""�������@�ӌ���=SUBSTITUTE(SUBSTITUTE(A1,B1,),D1,)�� Office�k��ܛ�����k���ĵ�һ�x���@�������˶�֪���� |
���P����
Windowsϵ�y�̳̙�Ŀ
��̳�����
ϵ�y���T�̳�
�����Tϵ�y������