- ���bIBM SPSS Statistic
- ���¾��a��SPSS�еđ��ð����D��ʹ�ý̳�
- SPSST�z��O�ò��E_SPSST�z���ο�
- SPSS�����ؘ�_SPSS��Ό��x��׃���ؽM
- SPSS�����ؘ�_SPSS��Ό��x�������ؽM
- SPSS�����ؘ�_SPSS�D�����Д���
- SPSS�l�ʅ^���c�����^�ֵIJ�ͬ�cԔ���f��
- SPSS�ĆΘӱ��������ӱ����䌦�ӱ�T�z���
- ���ͨ�^SPSS��헷ֲ��z��C�aƷ�ĺϸ�
- SPSS���¾��a��SPSS�ԄӾ��a���ɣ�
- ��Α���SPSS�Θӱ�T�zSPSS�z��
- ���ͨ�^SPSS�����ӱ�T�z�^�փɽM������

SPSS�����ϲ�_SPSS����M��׃���ϲ�
�l���r�g:2025-05-04 ����Դ:xp���dվ �g�[:
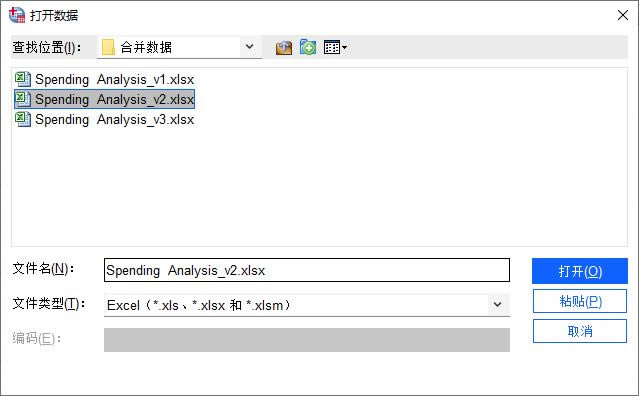
| SPSS��IBM��˾��Ʒ�����ṩ�˰��������ԽyӋ���Ɣ��ԽyӋ�����ӷ�������������ؚw�����ȶ�N�yӋ�������ܣ��������ı��������C���W���㷨����������ģ�͵ȡ�SPSS�Ľ����Ѻã����ڲ������܉���ُĔ�������ȡ���õĶ���ͷ������V�������ڽ������������t�W���Ј����˿ڡ����U�ȶ����о��I��Ҳ���ڮaƷ�|�����ơ����n���������ճ��yӋ����ȡ� �ڴ��ڶ�������Դ����r�£�������ʹ�õ�IBM SPSS Statistics�Ĕ����ϲ����ܣ�����������Դ�Ĕ����M�кϲ��� �������ռ��^�����r����Ҫ��ͬ�^���ˆT���_�ռ������ڔ����R�����A�Σ�����Ҫʹ�õ������ϲ��Ĺ��܌��@Щ��ͬ��Դ�Ĕ����ϲ��R�����������҂��������c�W��׃���ĺϲ��� һ�����_��ϲ��Ĕ��� ׃���ϲ��������nj���ͬ�����ļ��У���ͬ�����IJ�ͬ׃�������M�кϲ������电��A���������g���Ԅe�Ȕ�����������B�����˵^������Ȕ��������@Щ�������ǁ���ͬһ���������Ϳ���ͨ�^׃���ϲ������� ���ȣ���SPSS�зքe���_�ɂ���Ҫ�ϲ��Ĕ����ļ���
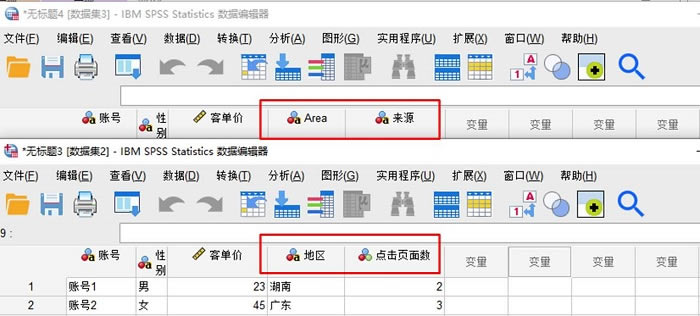
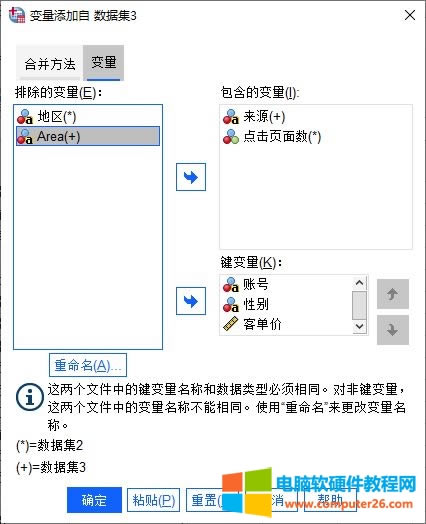
�D1�����_���� ��D2��ʾ�����Կ������ɂ������ļ��д������~̖���Ԅe���͆r������ͬ׃�����Լ�Area���^����Դ���c����攵�Ă���ͬ׃�������е^�cArea���H��ͬһ��׃������������ʽ��ͬ��
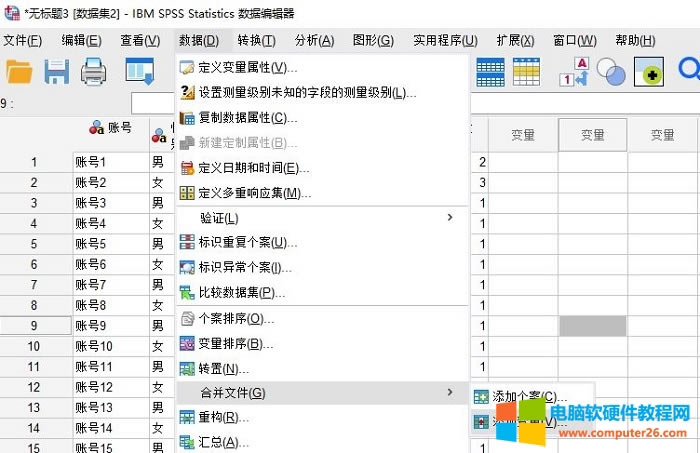
�D2������׃��� ����ʹ��׃���ϲ����� ��������D3��ʾ�����δ��_����-�ϲ��ļ�-����׃����ᘌ������ļ��Į�ͬ�c�M��׃���ϲ���
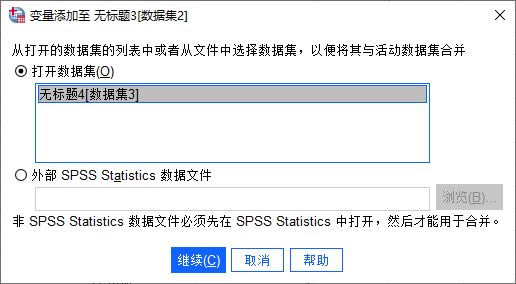
�D3��׃���ϲ����� ���ڮ�ǰ���_���ǔ�����2�������K�Ĕ������ϲ���������2�С���D4��ʾ���Ԕ�����2����A���c֮ǰ�Ѵ��_�Ĕ�����3�M�кϲ���
�D4��ָ���ϲ��Ĕ����ļ� ��������D5��ʾ�����_׃���x헿����M��׃���ϲ����O�á� ���У�׃����̖�к�+���ǔ�����2�в�������׃��������*���ǔ�����2�а�����׃�����O�õ�׃�����x���£� �ų���׃�������ɂ������ļ��д��ڲ�ģ����ںϲ������^������Ҫ����׃���� ������׃�������ɂ������ļ��д��ڲ�ģ����ںϲ������^������Ҫ������׃���� �I׃�������ɂ������ļ�ͬ�r������׃����
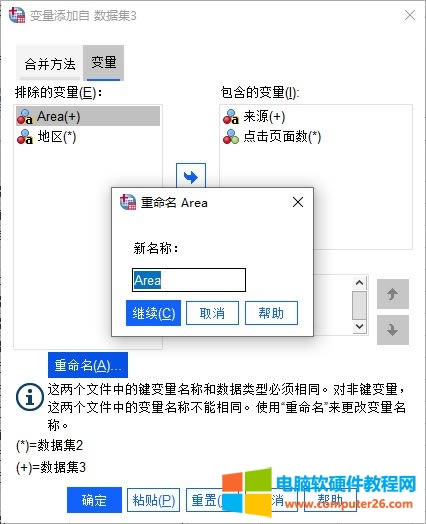
�D5���O��׃���ĺϲ���ʽ ����׃��“�^”�c“Area”���H��ͬһ׃�����Ɍ�����һ�����Ӟ�“������׃��”�����⣬߀����ͨ�^�������ķ�������“Area”��������“�^”��
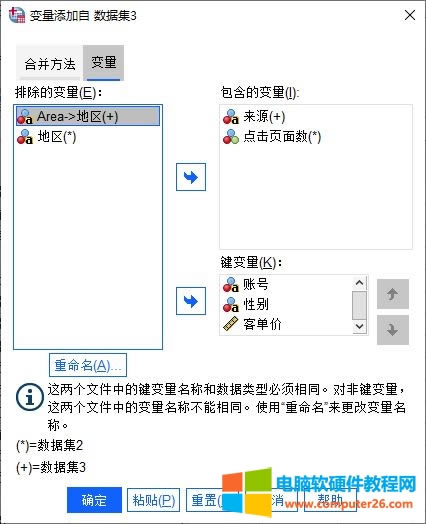
�D6��������׃�� ��D6��ʾ�����Կ���“Area”����������“�^”���������Ӟ�“������׃��”��
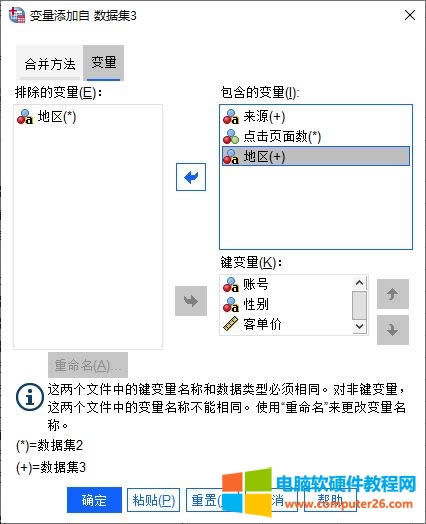
�D7�����׃���������� ��D7��ʾ���ڰ�����׃���У�“Area”׃���ѽ���������“�^”׃������Ȼ���҂�Ҳ����ֱ��ʹ�Ô�����2�а�����“�^”׃����
�D8���������������׃�� ������ϲ�������D8��ʾ�����Կ�����׃���ѽ��ϲ���ɡ����m���Ɍ��������Mһ����������������ȡ�
�D9�����׃���ĺϲ� �������S����Ӱ푵Ĉ��s־��SPSS�o���˸߶ȵ��u�r�� |
���P����
Windowsϵ�y�̳̙�Ŀ
��̳�����
ϵ�y���T�̳�
�����Tϵ�y������